








Research Interest
Computer vision, computational photography, machine learning
- Learning based image computation
- Image blur estimation
- Matching, optical flow, stereo matching, filter, super-resolution
- Sparse coding and L0 minimization
- Camera tracking and video depth/layer estimation
- Saliency and video understanding
- High-level recognition
Techniques Included in OpenCV 
- (Filter) Very fast Weighted Median Filter (WMF) (will be included in OpenCV) (C++ code) (64bit Matlab interface code) (VS project code)

- (Filter) Scale-aware Rolling Guidance Filter (RGF) (included in OpenCV since version 3.1.0) (MATLAB interface code) (VS project code) (Binaries)
- (Sparsity) L0 Image Smoothing (included in OpenCV since version 3.1.0) (Matlab code)
- (Color2Gray) Decolorization (included in OpenCV since version 3.0)
Challenges
- No. 1 of WAD Drivable Area Segmentation Challenge 2018
- No. 1 of LSUN Semantic Segmentation Challenge 2017
- No. 2 of Places Scene Parsing Challenge 2017
- No. 1 of COCO 2017 Detection Challenge in Instance Segmentation track
- No. 2 of COCO 2017 Detection Challenge in Object Detection track
- No. 1 of LSUN'17 Instance Segmentation Challenge
- No. 1 of ImageNet Scene Parsing Challenge 2016
- No. 3 of COCO 2015 Detection Challenge in Instance Segmentation track
Other Codes, Executables and Software
- (Semantic Segmentation) ICNet
- (Semantic Segmentation) PSPNet
- (Portrait Segmentation) First-of-Its-Kind Portrait Segmentation System
- (Deblurring)
 Robust
deblurring software with GPU enabled
Robust
deblurring software with GPU enabled 
- (Deblurring) L0 Non-uniform deblurring
- (Blur Detection) Just Noticeable Defocus Blur Detection
- (Joint Image Restoration) Cross-Field Joint Image Restoration via Scale Map (Matlab p-code)
- (Joint Image Filtering) Mutual-Structure for Joint Filtering (Matlab code)
- (Multiframe Superresolution)
Blur-involved superresolution (Matlab p-code)
- (Saliency Detection) Hierarchical saliency detection
- (Dictionary Learning) Online robust dictionary learning
- (Dictionary Learning) Scale adaptive dictionary learning
- (Optical Flow) Motion-detail preserving optical flow
- (Optical Flow) Segmentation-based optical flow estimation
- (Tone Mapping) HDR image tone mapping (Matlab code)
- (3D Reconstruction) ACTS: automatic camera tracking system
- (Super-resolution) Image upsampling
Benchmark Datasets
- (Portrait Matting) Portrait Matting Dataset (2016)
- (Portrait Segmentation) Portrait Segmentation Data and Code (2016)
- (Semantic Segmentation) PASCAL-scribble dataset (2016)
- (Saliency Detection) Complex Scene
Saliency Dataset (CSSD) and Extended CSSD (ECSSD) (2015)
- (Blur Detection) Blur Detection Dataset (2014)
- (Weather Classification) Sunny and Cloundy Image Dataset (2014)
- (Abnormal Event Detection) Avenue Dataset (2013)
Research Highlights
-
Semantic Segmentation
-

Augmented Feedback in Semantic Segmentation under Image Supervision (2016)
Training neural networks for semantic segmentation is data hungry. Meanwhile annotating a large number of pixel-level segmentation masks needs enormous human effort. In this paper, we propose a framework with only image-level supervision. It unifies semantic segmentation and object localization with important proposal aggregation and selection modules. They greatly reduce the notorious error accumulation problem that commonly arises in weakly supervised learning. Our proposed training algorithm progressively improves segmentation performance with augmented feedback in iterations.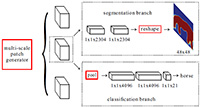
Multi-scale Patch Aggregation (MPA) for Simultaneous Detection and Segmentation (2016)
Aiming at simultaneous detection and segmentation (SDS), we propose a proposal-free framework, which detect and segment object instances via mid-level patches. We design a unified trainable network on patches, which is followed by a fast and effective patch aggregation algorithm to infer object instances. Our method benefits from end-to-end training. Without object proposal generation, computation time can also be reduced. In experiments, our method yields results 62.1% and 61.8% in terms of mAPr on VOC2012 segmentation val and VOC2012 SDS val, which are state-of-the-art at the time of submission.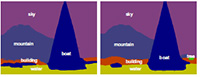
ScribbleSup for Semantic Segmentation (2016)
Large-scale data is of crucial importance for learning semantic segmentation models. But annotating per-pixel masks is a tedious and inefficient procedure. We note that for the topic of interactive image segmentation, scribbles are very widely used in academic research and commercial software, and are recognized as one of the most userfriendly ways of interacting. In this paper, we propose to use scribbles to annotate images, and develop an algorithm to train convolutional networks for semantic segmentation supervised by scribbles. -
Deep Convolutional Neural Networks for Image Operations
-
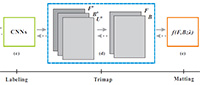
Deep Automatic Portrait Matting (2016)
We propose an automatic image matting method for portrait images. This method does not need user interaction. A new end-to-end convolutional neural network (CNN) based framework is proposed taking the input of a portrait image. It outputs the matte result. Our method considers not only image semantic prediction but also pixel-level image matte optimization. A new portrait image dataset is constructed with our labeled matting ground truth.
Automatic Portrait Segmentation for Image Stylization (2016) (Petapixel report)
Portraiture is a major art form in both photography and painting. In most instances, artists seek to make the subject stand out from its surrounding, for instance, by making it brighter or sharper. In the digital world, similar effects can be achieved by processing a portrait image with photographic or painterly filters that adapt to the semantics of the image. While many successful user-guided methods exist to delineate the subject, fully automatic techniques are lacking and yield unsatisfactory results. Our paper first addresses this problem by introducing a new automatic segmentation algorithm dedicated to portraits.
Video Super-Resolution via Deep Draft-Ensemble Learning (2015)
We propose a new direction for fast video superresolution (VideoSR) via a SR draft ensemble. Our method contains two main components – i.e., SR draft ensemble generation and its optimal reconstruction. The first component is to renovate traditional feedforward reconstruction pipeline and greatly enhance its ability to compute different super-resolution results considering large motion variation and possible errors arising in this process. Then we combine SR drafts through the nonlinear process in a deep convolutional neural network (CNN).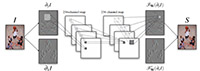
Deep Edge-Aware Filters (2015)
There are many edge-aware filters varying in their construction forms and filtering properties. It seems impossible to uniformly represent and accelerate them in a single framework. We made the attempt to learn a big and important family of edge-aware operators from data. Our method is based on a deep convolutional neural network with a gradient domain training procedure, which gives rise to a powerful tool to approximate various filters without knowing the original models and implementation details.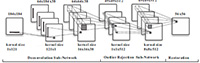
Deep Convolutional Neural Network for Image Deconvolution (2014)
Real blur degradation seldom complies with an ideal linear convolution model due to camera noise, saturation, image compression, to name a few. Instead of perfectly modeling outliers, which is rather challenging from a generative model perspective, we develop a deep convolutional neural network to capture the characteristics of degradation. We note directly applying existing deep neural networks does not produce reasonable results. Our solution is to establish the connection between traditional optimization-based schemes and a neural network architecture where a novel, separable structure is introduced as a reliable support for robust deconvolution against artifacts. -
Making Use of Insignificant Defocus Blur in Images
-

Break Ames Room Illusion: Depth from General Single Images (2015)
Photos compress 3D visual data to 2D. However, it is still possible to infer depth information even without sophisticated object learning. We propose a solution based on small-scale defocus blur inherent in optical lens and tackle the estimation problem by proposing a non-parametric matching scheme for natural images. It incorporates a matching prior with our newly constructed edgelet dataset using a non-local scheme, and includes semantic depth order cues for physically based inference.
Just Noticeable Defocus Blur Detection and Estimation (2015)
We tackle a fundamental yet challenging problem to detect and estimate just noticeable blur (JNB) caused by defocus that spans a small number of pixels in images. This type of blur is very common during photo taking. Although it is not strong, the slight edge blurriness contains informative clues related to depth. We found existing blur descriptors, based on local information, cannot distinguish this type of small blur reliably from unblurred structures. We propose a simple yet effective blur feature via sparse representation and image decomposition...
Discriminative Blur Detection Features (2014)
Ubiquitous image blur brings out a practically important question -- what are effective features to differentiate between blurred and unblurred image regions. We address it by studying a few blur feature representations in image gradient, Fourier domain, and data-driven local filters. Our results are applied to several applications, including blur region segmentation, deblurring, and blur magnification. -
Smoothing and Filter
-

Mutual-Structure for Joint Filtering (2015)
We propose the concept of mutual-structure, which refers to the structural information that is contained in both images and thus can be safely enhanced by joint filtering, and an untraditional objective function that can be efficiently optimized to yield mutual structure. Our method results in necessary and important edge preserving, which greatly benefits depth completion, optical flow estimation, image enhancement, stereo matching, to name a few.
Rolling Guidance Filter (2014)
We propose a new framework to filter images with the complete control of detail smoothing under a scale measure. It is based on a rolling guidance implemented in an iterative manner that converges quickly. Our method is simple in implementation, easy to understand, fully extensible to accommodate various data operations, and fast to produce results. Our implementation achieves realtime performance and produces artifact-free results in separating different scale structures.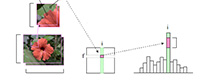
Very Fast Weighted Median (2014)
Weighted median has been employed in a wide range of computer vision solutions for its beneficial properties in sparsity representation. We propose a few efficient schemes to reduce computation complexity. Our contribution is on a new joint-histogram representation, median tracking, and a new data structure that enables fast data access. The running time is largely shortened from several minutes to less than 1 second. The source code is provided in the project website.
Texture Smoothing via Relative Total Variation (2012)
It is ubiquitous that meaningful structures are formed by or appear over textured surfaces. Extracting them under the complication of texture patterns, which could be regular, near-regular, or irregular, is very challenging, but of great practical importance. We propose new inherent variation and relative total variation measures, which capture the essential difference of these two types of visual forms, and develop an efficient optimization system to extract main structures. Our approach finds a number of new applications.
Image Smoothing via L0 Gradient Minimization (2011)
A new image editing method, particularly effective for sharpening major edges by increasing the steepness of transitions while eliminating a manageable degree of low-amplitude structures, is proposed. The seemingly contradictive effect is achieved in an unconventional optimization framework making use of L0 gradient minimization, which can globally control how many non-zero gradients are resulted to approximate prominent structures in a structure-sparsity-management manner. It finds many applications. -

It is common that users draw strokes, as control samples, to modify color, structure, or tone of a picture. We discover inherent limitation of existing methods for their implicit requirement on where and how the strokes are drawn, and present a new system that is principled on minimizing the amount of work put in user interaction. Our method automatically determines the influence of edit samples across the whole image jointly considering spatial distance, sample location, and appearance. It greatly reduces the number of samples that are needed. Our method is broadly beneficial to applications adjusting visual content. -
Multi-Modal and Multi-Spectral Images
-

Multi-modal and Multi-spectral Registration (2014)
We address the matching problem considering structure variation possibly existing in these multi-modal and multi-spectral images and introduce new model and solution. Our main contribution includes designing the descriptor named robust selective normalized cross correlation (RSNCC) to establish dense pixel correspondence in input images and proposing its mathematical parameterization to make optimization tractable. A computationally robust framework including global and local matching phases is also established.
Cross-Field Joint Image Restoration (2013)
Color, infrared and flash images captured in different fields can be employed to effectively eliminate noise and other visual artifacts. We propose a two-image restoration framework considering input images from different fields, for example, one noisy color image and one dark-flashed near-infrared image. We also introduce a novel scale map as a competent representation to explicitly model derivative-level confidence and propose new functions and a numerical solver to effectively infer it. -
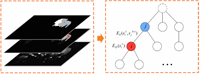
When dealing with objects with complex structures, saliency detection confronts a critical problem - namely that detection accuracy could be adversely affected if salient foreground or background in an image contains small-scale high-contrast patterns. This issue is common in natural images and forms a fundamental challenge for prior methods. We tackle it from a scale point of view and propose a multi-layer approach to analyze saliency cues. The final saliency map is produced in a hierarchical model. A new dataset is also constructed. -
Motion Blur Removal
-

Inverse Kernel (2014)
We propose an efficient spatial deconvolution method that can incorporate sparse priors to suppress noise and visual artifacts. It is based on estimating inverse kernels that are decomposed into a series of 1D kernels. An augmented Lagrangian method is adopted, making inverse kernel be estimated only once for each optimization process. Our method is fully parallelizable.
Forward Motion Deblurring (2013)
We handle a special type of motion blur considering that cameras move primarily forward or backward. Solving this type of blur is of unique practical importance since nearly all car, traffic and bike-mounted cameras follow out-of-plane translational motion. We start with the study of geometric models and analyze the difficulty of existing methods to deal with them. We also propose a solution accounting for depth variation.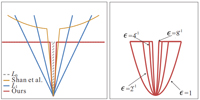
L0 Deblurring (2013)
We show that the success of previous maximum a posterior (MAP) based blur removal methods partly stems from their respective intermediate steps, which implicitly or explicitly create an unnatural representation containing salient image structures. We propose a generalized and mathematically sound L0 sparse expression, together with a new effective method, for motion deblurring.
Depth-Aware and Non-uniform Blur Removal (2012)
Motion blur removal from images sometimes need to estimate spatially-varying point spread functions (PSFs). We address two critical problems in this process. One is PSF estimation in small regions. The other is erroneous PSF rejection based on the shock filtering invariance of natural images. Our framework applies to general single-image and stereo-image spatially-varying deblurring.
Large Blur Removal (2010)
We discuss a few new motion deblurring problems that are significant to kernel estimation and non-blind deconvolution. We found that strong edges do not always profit kernel estimation, but instead under certain circumstance degrade it. This finding leads to a new metric to measure the usefulness of image edges in motion deblurring and a gradient selection process to mitigate their possible adverse effect. We also propose an efficient and high-quality kernel estimation method based on using the spatial prior and the iterative support detection (ISD) kernel refinement, which avoids hard threshold of the kernel elements to enforce sparsity.-
More Deblurring Projects...
-
-
Combining Sketch and Tone for Pencil Drawing Production (2012) NPAR Best Paper Award
-

We propose a new system to produce pencil drawings from natural images. The results contain various natural strokes mimicking human styles and are structurally representative. They are accomplished by novelly combining the tonal and sketch structures, which complement each other in generating visually constrained results. Prior knowledge on pencil drawing is also incorporated, making the two basic functions robust against noise, strong texture, and significant illumination variation. -
Optical Flow Estimation (2008, 2010, 2012)
-

We develop a few optical flow estimation methods usable for video motion estimation and other applications. They are based on segmentation and on a novel extended coarse-to-fine (EC2F) refinement framework. The effectiveness of our algorithms is demonstrated using the Middlebury optical flow benchmark and by experiments on challenging examples that involve large-displacement motion. -

Decolorization - the process to transform a color image to a grayscale one - is a basic tool in digital printing, stylized black-and-white photography, and in many single channel image processing applications. We propose an optimization approach aiming at maximally preserving the original color contrast. Our main contribution is to alleviate a strict order constraint for color mapping based on human vision system, which enables the employment of a bimodal distribution to constrain spatial pixel difference and allows for automatic selection of suitable gray scale in order to preserve the original contrast. -
More Projects... (2003-2008)









Editorial Boards
- IEEE Transactions on Pattern Analysis and Machine Intelligence (TPAMI), Editorial Board
- International Journal of Computer Vision (IJCV), Editorial Board
- Advances in Computer Vision and Pattern Recognition, Advisory Board
Papers Committees
- Area Chair, European Conference on Computer Vision (ECCV) 2018
- Area Chair, IEEE International Conference on Computer Vision (ICCV) 2017
- Area Chair, IEEE Conference on Computer Vision and Pattern Recognition (CVPR) 2017
- 10K Best Paper Award Committee, IEEE ICME
- Technical Paper Program Committee member, SIGGRAPH 2016
- Area Chair, IEEE Conference on Computer Vision and Pattern Recognition (CVPR) 2016
- Technical Paper Program Committee member, SIGGRAPH Asia 2015
- Technical Paper Program Committee member, SIGGRAPH Asia 2014
- Paper Committee member, IEEE International Conference on Computational Photography (ICCP) 2014, 2015, 2016
- Area Chair, IEEE International Conference on Computer Vision (ICCV) 2013
- Posters & Demos Chair, IEEE International Conference on Computational Photography (ICCP) 2013
- Paper Committee member, IEEE International Conference on Computational Photography (ICCP) 2013
- Course Co-Chair, SIGGRAPH Asia 2012
- Area Chair, International Conference on Pattern Recognition (ICPR) 2012
- Area Chair, Asian Conference on Computer Vision (ACCV) 2012
- Program Committee member, IEEE International Conference on Image Processing (ICIP) 2012
- Area Chair, IEEE International Conference on Computer Vision (ICCV) 2011
- Program Committee member, 3DV 2013, 2014, 2015
- Program Committee member, Pacific Graphics 2010, 2011, 2012, 2013, 2014, 2015, 2016
- Program Committee member, 3DPVT 2010 and 3DIMPVT 2011
- Organization Chair, Workshop on Interactive Computer Vision (In conjunction with ICCV) 2007
- Publication Chair, ACM VRCIA 2006
- Program Committee member, IEEE International Conference on Computer Vision (ICCV) 2005, 2007, 2009
- Program Committee member, European Conference on Computer Vision (ECCV) 2006, 2008, 2010
- Program Committee member, IEEE Conference on Computer Vision and Pattern Recognition (CVPR) 2008, 2009, 2010, 2011
Grants from Government Funding Agencies
- Principal Investigator, Large Scale Semantic Image Segmentation and Classification Platform, Innovation and Technology Fund (ITF), 2017-2018.
- Co-Investigator, Personal Identification using Contactless Live 3D Finger Scans, RGC General Research Fund (GRF), 2013-2016.
- Principal Investigator, Urban-Scale Structure-from-Motion with Feature Similarity Discovery, RGC General Research Fund (GRF), 2013-2016.
- Principal Investigator, Optical Flow for Natural Video Editing Interface, Microsoft Research Grant, 2012-2014.
- Co-Investigator, Techniques for Complicated Scene Modeling and Super-high Resolution Rendering, NSFC key project, 2012-2017.
- Principal Investigator, Robust Dense Motion Estimation for Natural Image Sequences in Computer Vision, RGC General Research Fund (GRF), 2011-2014.
- Principal Investigator, Intelligent Video Revampment and Upsampling, Innovation and Technology Fund (ITF), 2011-2012.
- Principal Investigator, High-quality Bilayer Segmentation with Motion/Depth Estimation, RGC General Research Fund (GRF), 2010-2013.
- Principal Investigator, GPU Based Video Editing with Depth Inference, RGC Direct Grant, 2010-2011.
- Principal Investigator, Single Image Motion Deblurring in a Local-Structure-Oriented Framework, RGC General Research Fund (GRF), 2008-2010.
- Principal Investigator, Optimizing General Image Stitching, RGC General Research Fund (GRF), 2007-2009.
- Co-Investigator, Image/Video based Soft Fabric Redressing on Objects/Environment for Interactive E-Commence Applications, RGC General Research Fund (GRF), 2007-2010.
- Principal Investigator, High Dynamic Range Image and Video Rendering, Compression, and Display, SHIAE Research Grant, 2007-2009.
- Principal Investigator, Soft Color Segmentation Using Alternative Optimization, RGC Earmarked Grant (GRF), 2006-2008.
- Principal Investigator, Texture Synthesis and Image Completion on Programmable Graphics Hardware, Microsoft Research Grant, 2006-2008.
- Principal Investigator, Enhanced image and video completion, RGC Direct Grant, 2004-2006.
Patents
- Drag-and-drop pasting for seamless image composition, U.S. Patent 8351713
- Luminance correction, U.S. Patent 7317843
- Poisson matting for images, U.S. Patent 7636128
- Digital cameras with luminance correction, U.S. Patent 7463296