Hadoop -- Word Count Example
Introduction
As known, world count is a typical entry example for learning Hadoop. In this section, we will show how to write a Hadoop application for solving word count problem and how to run it with Hadoop system from scratch.
If you have not set up an environemnt with Hadoop MR, go to this tutorial and get the environment ready first. All the operations in this section will be done in that environment.
Eclipse will be used to develop this simple program with some configurations.
Write Hadoop application on Eclipse
First, create a Java project, by double clicking Eclipse shortcut on desktop, clicking File -> New -> Java Project in the Eclipse window, and assigning project name (i.e. WordCount) in the dialogue. Note that a folder called src will be automatically created, which is used to store source files.
Second, create a package called polyu.bigdata under the src folder, by clicking File -> New -> Pakcage and assigning name as polyu.bigdata in the dialogue.
Third, create a class called WordCount, by clicking File -> New -> Class and assigning name as WordCount in the dialogue. And then copy the code below to WordCount.java and save it.
package polyu.bigdata;
import java.io.IOException;
import java.util.StringTokenizer;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
public class WordCount {
//Mapper which implement the mapper() function
public static class TokenizerMapper extends Mapper<Object, Text, Text, IntWritable> {
private final static IntWritable one = new IntWritable(1);
private Text word = new Text();
public void map(Object key, Text value, Context context) throws IOException, InterruptedException {
StringTokenizer itr = new StringTokenizer(value.toString());
while (itr.hasMoreTokens()) {
word.set(itr.nextToken());
context.write(word, one);
}
}
}
//Reducer which implement the reduce() function
public static class IntSumReducer extends Reducer<Text, IntWritable, Text, IntWritable> {
private IntWritable result = new IntWritable();
public void reduce(Text key, Iterable<IntWritable> values, Context context) throws IOException, InterruptedException {
int sum = 0;
for (IntWritable val : values) {
sum += val.get();
}
result.set(sum);
context.write(key, result);
}
}
//Driver class to specific the Mapper and Reducer
public static void main(String[] args) throws Exception {
Configuration conf = new Configuration();
Job job = Job.getInstance(conf, "word count");
job.setJarByClass(WordCount.class);
job.setMapperClass(TokenizerMapper.class);
job.setReducerClass(IntSumReducer.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(IntWritable.class);
job.setMapOutputKeyClass(Text.class);
job.setMapOutputValueClass(IntWritable.class);
FileInputFormat.addInputPath(job, new Path(args[0]));
FileOutputFormat.setOutputPath(job, new Path(args[1]));
System.exit(job.waitForCompletion(true) ? 0 : 1);
}
}
Notice that there are some red wavy lines underneath imported packages, which indicates the error "Fail to import class"
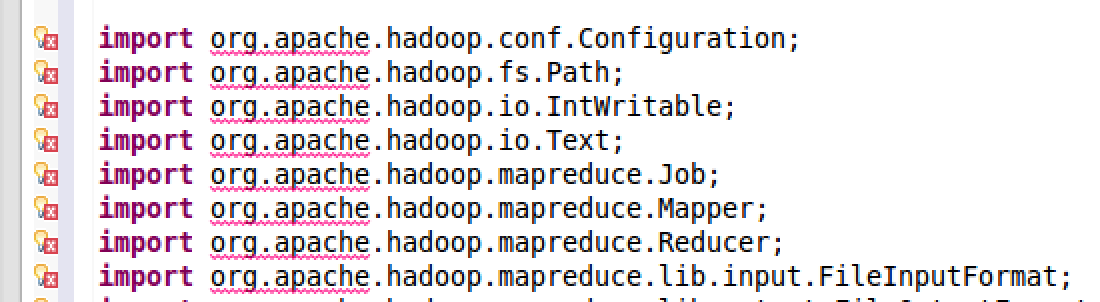
It is because of the missing Hadoop library. So the Hadoop Java library must be imported in order to resolve the dependency problem.
Right click WordCount project , select "Properties"
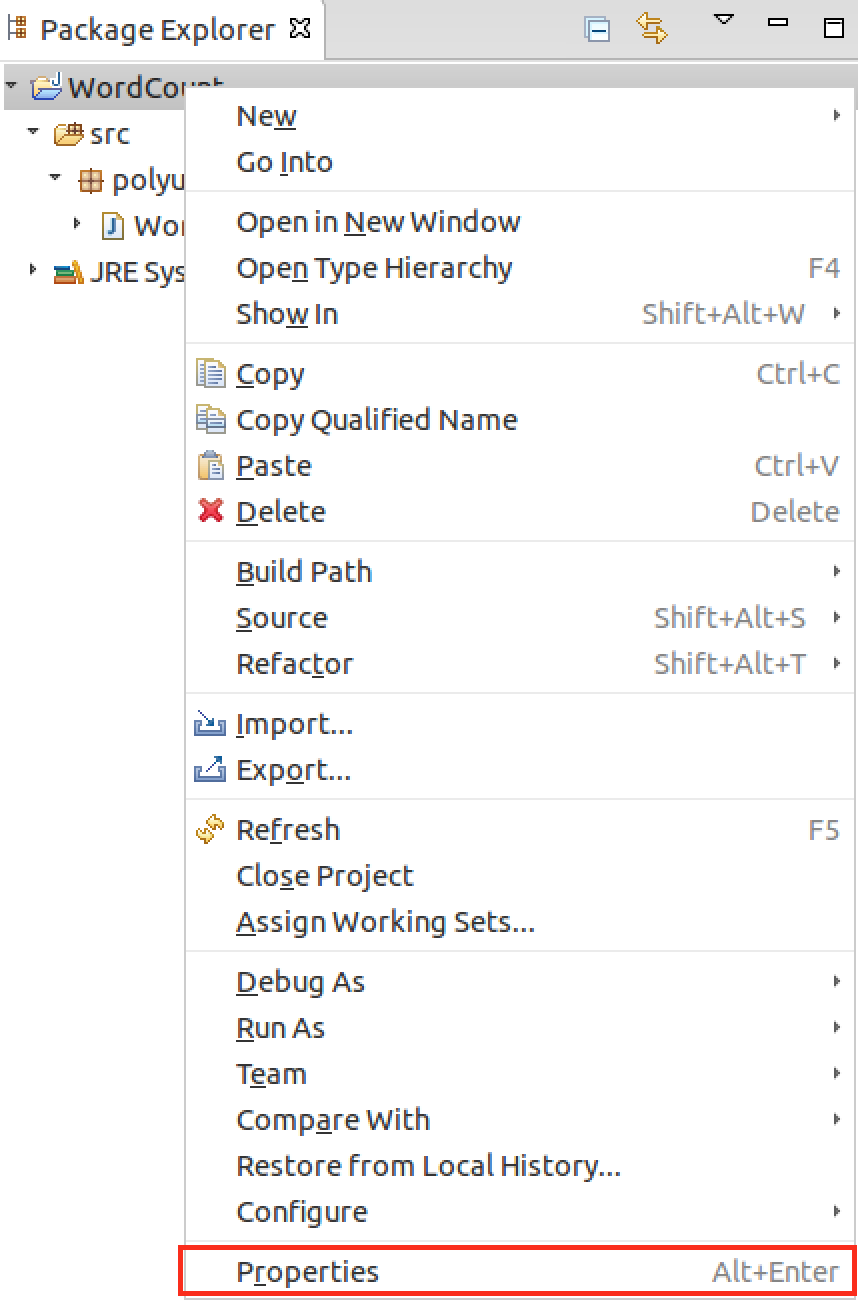
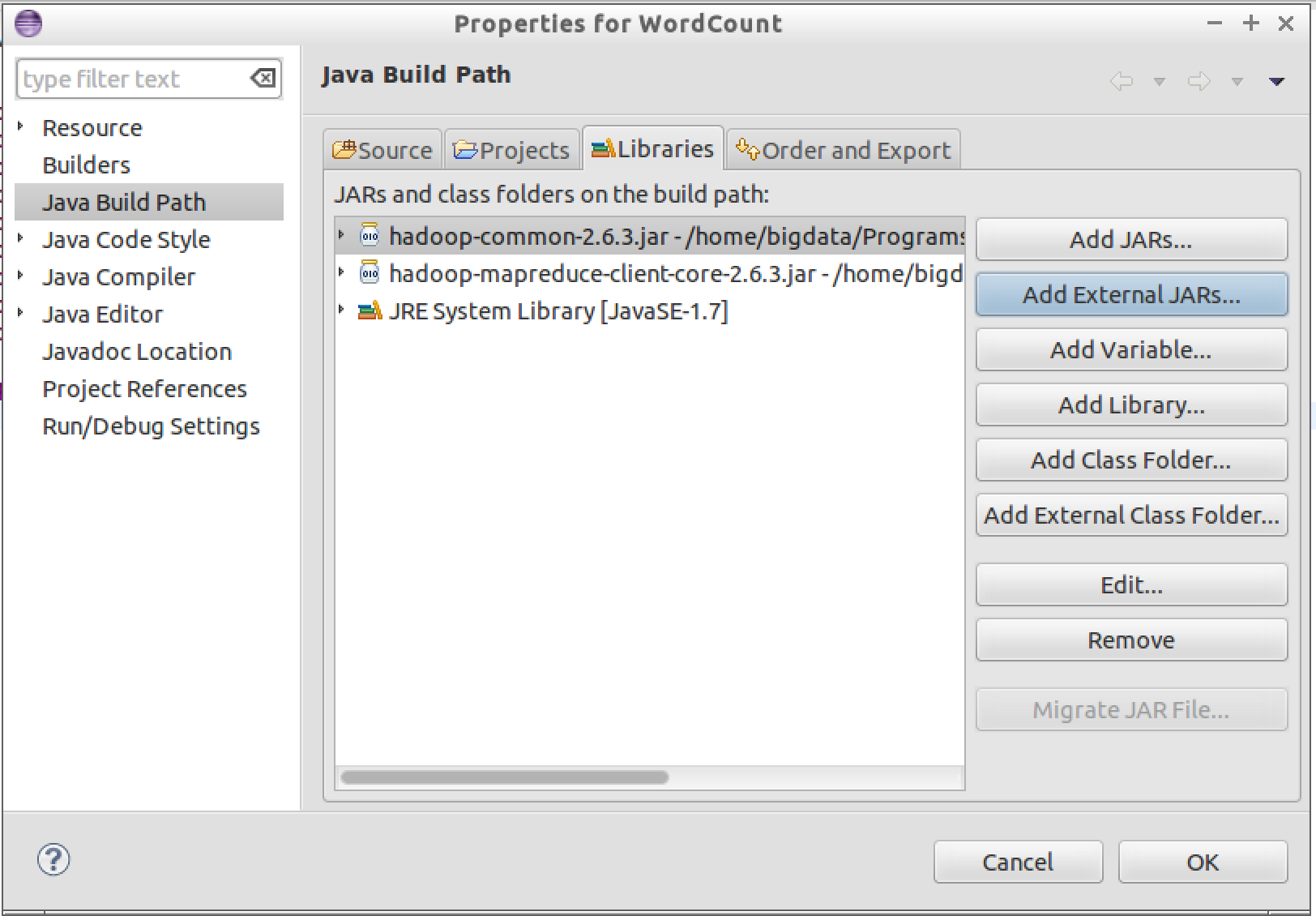
Select Java Build Path->Configure Build Path->Libraries->Add External JARs import jars "hadoop-common-2.6.3.jar" and "hadoop-mapreduce-client-core-2.6.3.jar" which located at :
/home/bigdata/Programs/hadoop/share/hadoop/common/hadoop-common-2.6.3.jar
/home/bigdata/Programs/hadoop/share/hadoop/mapreduce/hadoop-mapreduce-client-core-2.6.3.jar
After both jars are imported, "Java Build Path" should look like:
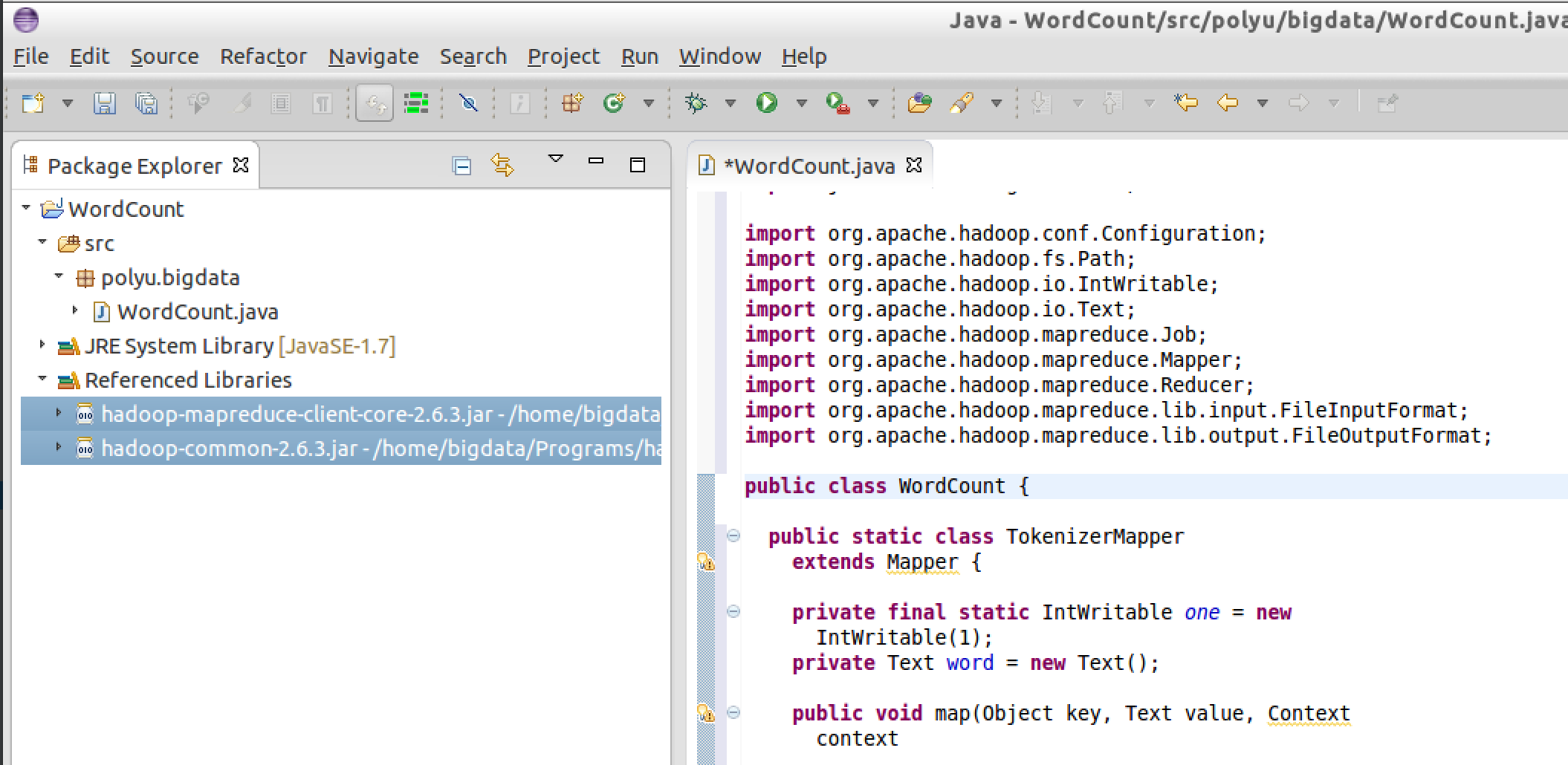
Red wavy lines should disappear now, which means the dependency errors are solved.
Export jar file
Next export the source file as a jar file and upload it to Hadoop system to run it.
Right click WordCount project, then click Export, it is like this:
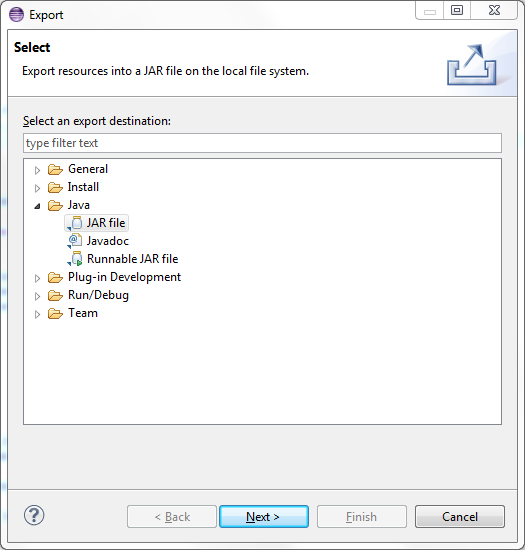
Select JAR file, click Next,
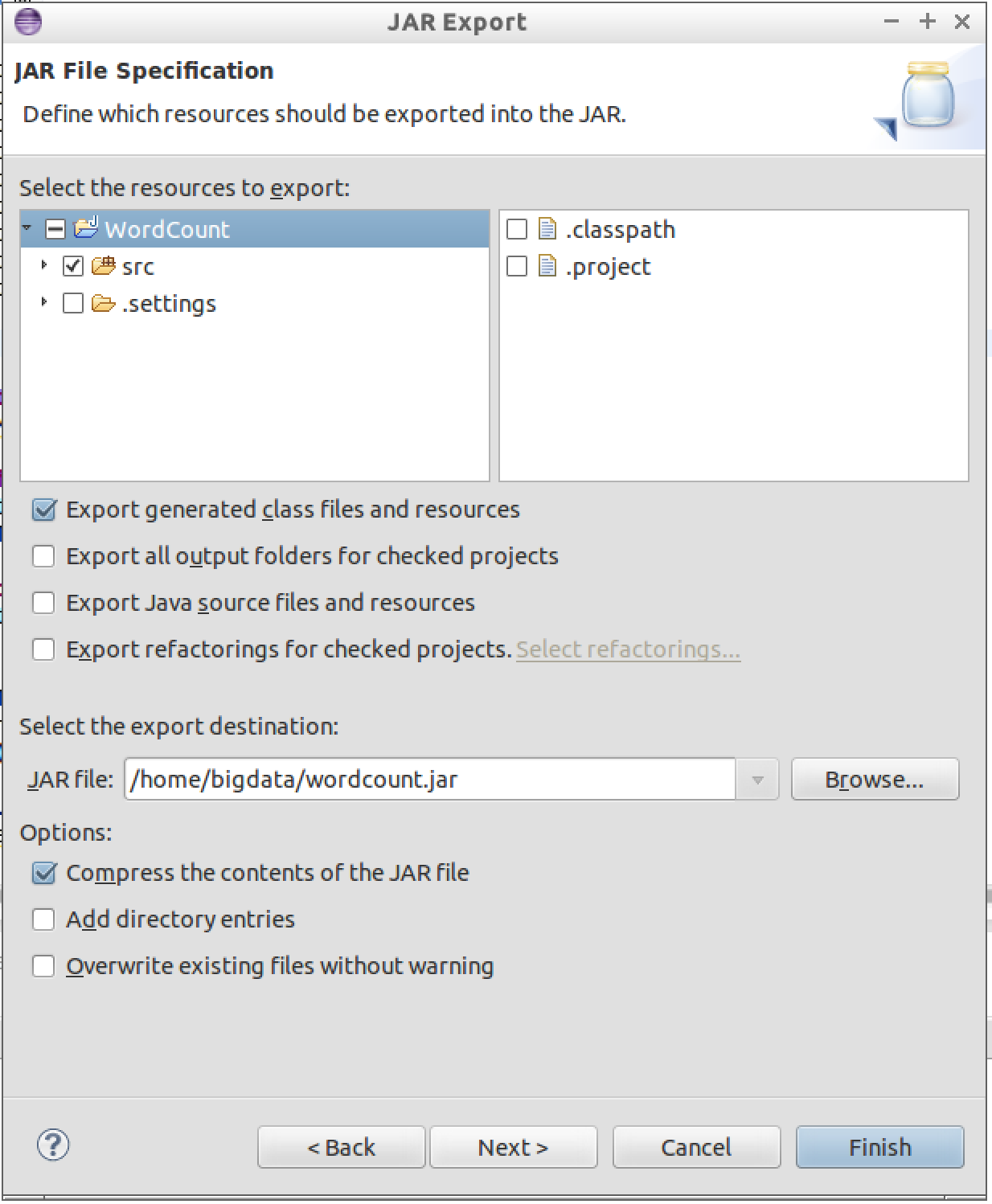
Make sure your settings are the same as what are shwon in the picture. Make sure you select the choose all export destination in src folder. Select the export destination to /home/bigdata/wordcount.jar Then click Finish, the jar file will be exported successfully.
Start Hadoop
To run Hadoop application, the Hadoop system must be started first.
Switch to the guest system, open LXTerminal in applications/Accessories, type the following commands.
Start Hadoop
~/Programs/hadoop/sbin/start-all.sh
Check Hadoop status
Next open firefox browser in the guest system, access the following urls, and view the running status of Hadoop.
http://localhost:8088
http://localhost:50070
Upload data to Hadoop File System(HDFS)
Before executing the word count program, we also need a text file to process, download this hadoop.txt from here and save the file to /home/bigdata
The Hadoop must be started first, then type the following commands in terminal.
Create folder for data on HDFS
~/Programs/hadoop/bin/hadoop fs -mkdir -p /user/bigdata/wordcount/input
Upload data to HDFS
~/Programs/hadoop/bin/hadoop fs -put ~/hadoop.txt /user/bigdata/wordcount/input
Execute Hadoop application
Run program
~/Programs/hadoop/bin/hadoop jar ~/wordcount.jar polyu.bigdata.WordCount /user/bigdata/wordcount/input /user/bigdata/wordcount/output
If it runs successfully, the following information will pops up:
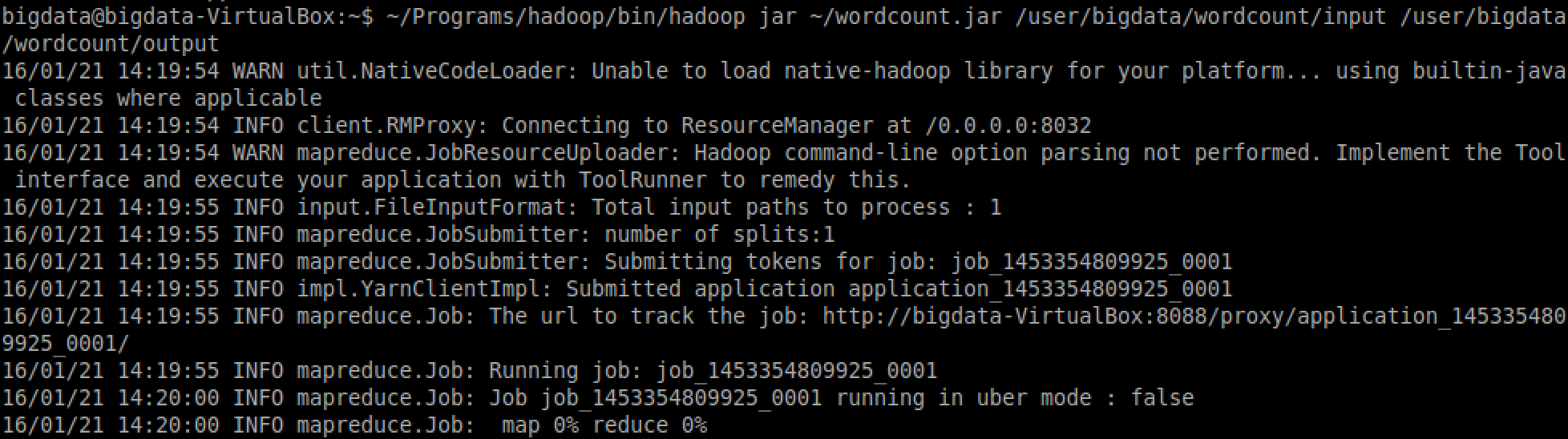
View execution status
During the execution, we can open firefox of the guest system and access tne url below.
http://localhost:8088
Check the execution progress, it should look like this:
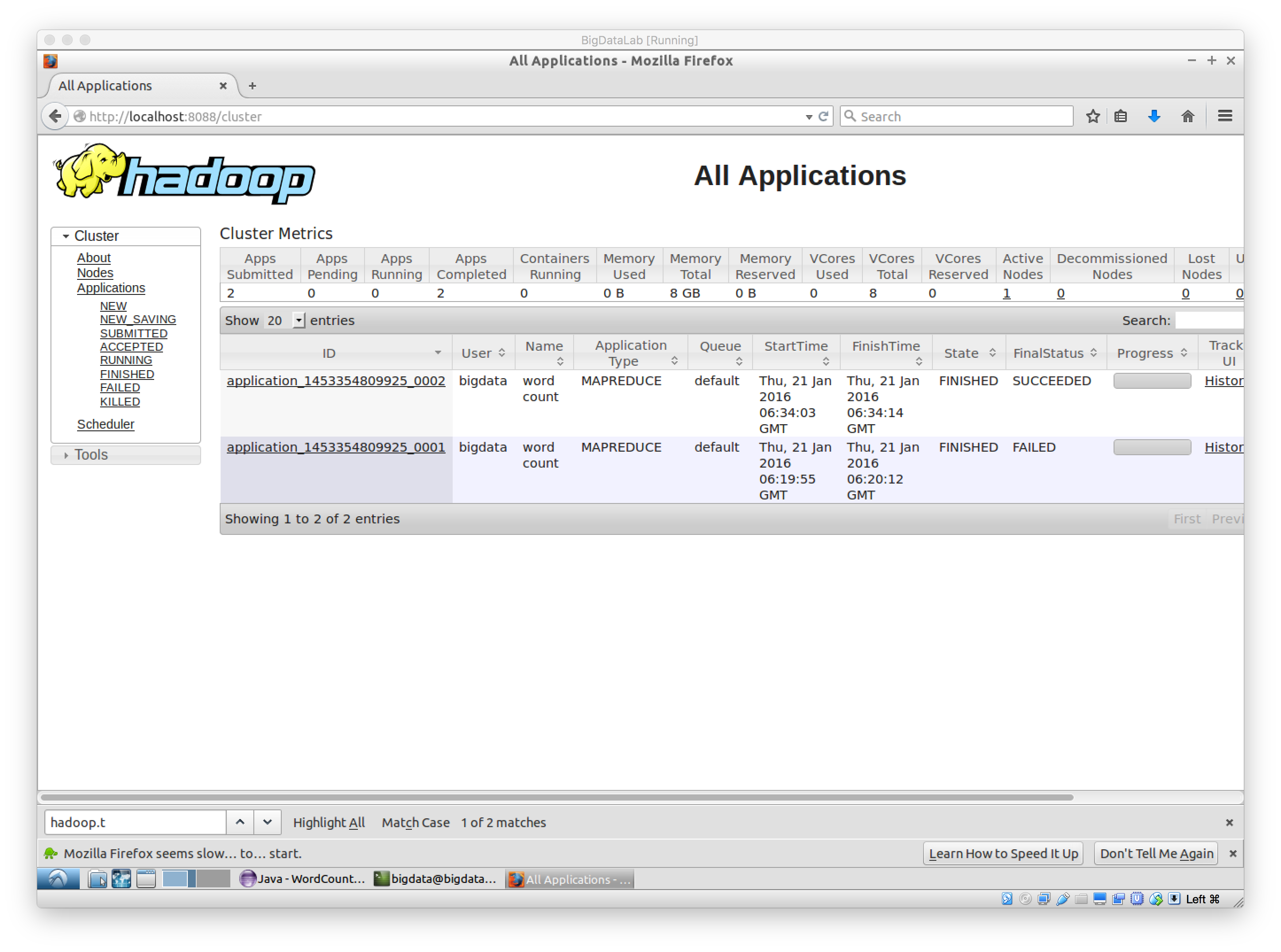
Check output
To check the result, we need to first download the output folder from HDFS by using the command below.
~/Programs/hadoop/bin/hadoop fs -get /user/bigdata/wordcount/output ~/
The output folder now is in the home folder of your guest system, you can use any text editor to open the result file, the result file name is part-r-00000.
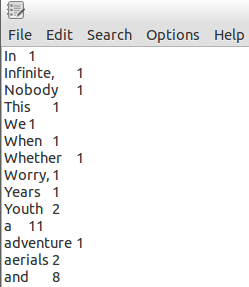
The result is like this:
Repeat running the program
If you want to run this example again, first delete the output folder from local and HDFS, then run the program, which can be achieved by the following commands.
Delete local output folder
rm -rf ~/output
Delete HDFS output folder
~/Programs/hadoop/bin/hadoop fs -rmr /user/bigdata/wordcount/output
Run the program again
~/Programs/hadoop/bin/hadoop jar ~/wordcount.jar polyu.bigdata.WordCount /user/bigdata/wordcount/input /user/bigdata/wordcount/output
Debug Hadoop Program
The core methods we need to debug are map and reduce. Suppose we want to know what key map is processing and what key and value reduce is processing,
we can add some output information in the map and reduce function.
We still take WordCount as the example, we add statement in map like this:
while (itr.hasMoreTokens()) {
word.set(itr.nextToken());
System.out.println("Map phase: We are processing word " + word);
context.write(word, one);
}
we also add one statement in reduce like this:
for (IntWritable val : values) {
System.out.println("Reduce phase: The key is " + key + " The value is " + val.get());
sum += val.get();
}
Now we need to export the jar and run it again.
Then we can use Firefox to open to see whether the job is completed or not
http://localhost:8088
After the job is completed, record down the ID
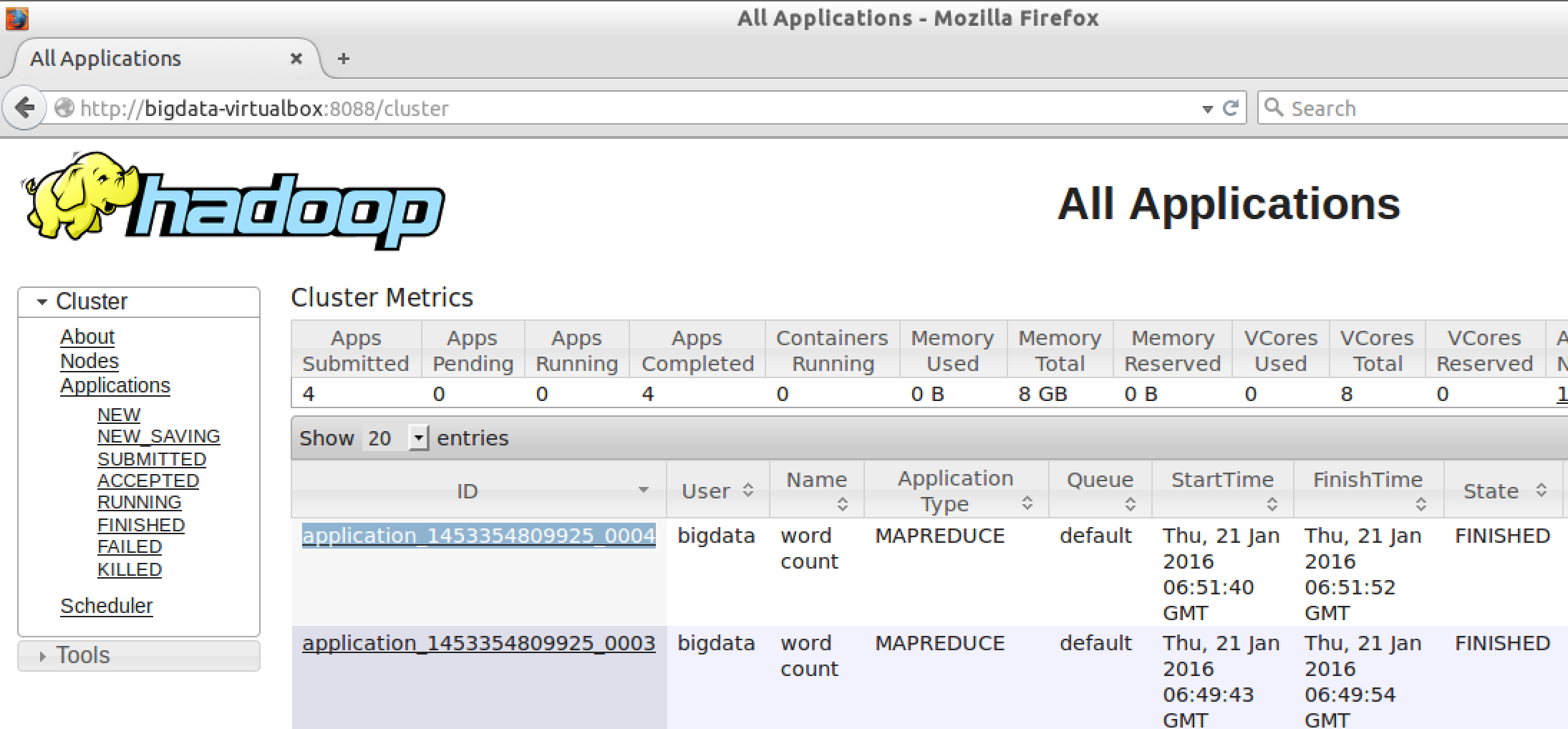
Open a terminal, go to folder:
cd ~/Programs/hadoop/logs/userlogs/{The job ID e.g application_1453354809925_0004}
ls
You will see a list of folder:

There is a file call "stdout" in each container_XXXXXX folder. Use the command below to print things out.
cat */stdout
You should see the standard output (i.e System.out.print()) of mapper and reducer
Exercises
1. Write a new word count program that only count the words starting with 'a';
2. Write a new word count program that only count the words whose length is longer than 10.
Reference Answers:
1, only modify map function to this:
public void map(Object key, Text value, Context context) throws IOException, InterruptedException {
StringTokenizer itr = new StringTokenizer(value.toString());
while (itr.hasMoreTokens()) {
String wordToCheck = itr.nextToken();
if (wordToCheck.startsWith("a")) {
word.set(wordToCheck);
context.write(word, one);
}
}
}
2. also change one line from above code snippet,
if (wordToCheck.length() > 10) {