Husky
The Husky project aims to build a more expressive and most importantly, more efficient system for distributed data analytics.
Download Husky (core components)**This academic version provides basic but essential features such as fine-grained object interaction, coarse-grained transformation (e.g., map, reduce), iterative graph analytics and asynchronous machine learning. Husky is open-source in GitHub.
Fast
Greater performance with same hardware!
Husky has a highly optimized backend. We always try to exploit more performance from limited computing resources.
Besides, the Husky computing model allows more efficient algorithms to be programmed.
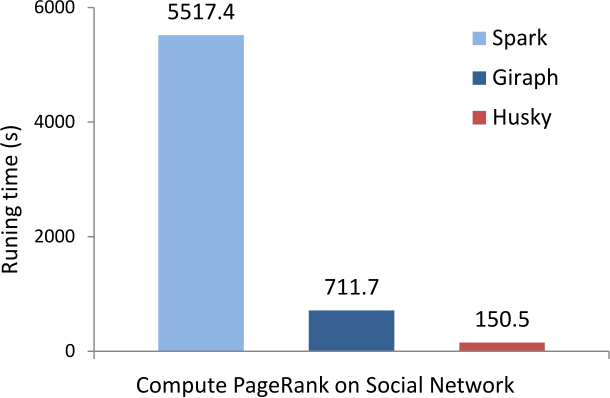
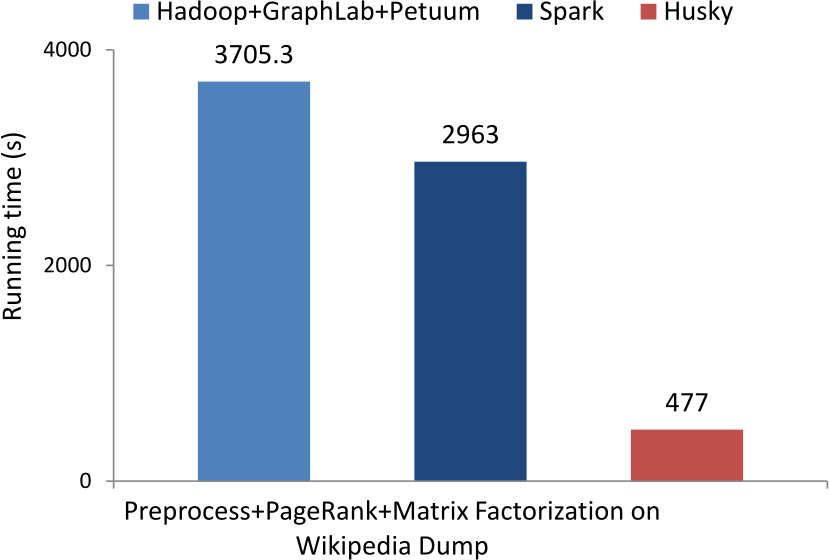
General
One unified platform, various purposes.
Husky supports a variety of applications, including MapReduce-style ETL, text mining, graph analytics, machine learning(both synchronous and asynchronous).
Furthermore, Husky can cooperate seamlessly with many existing systems, and integrate nicely in the Hadoop eco-system. We are working to support more external systems.
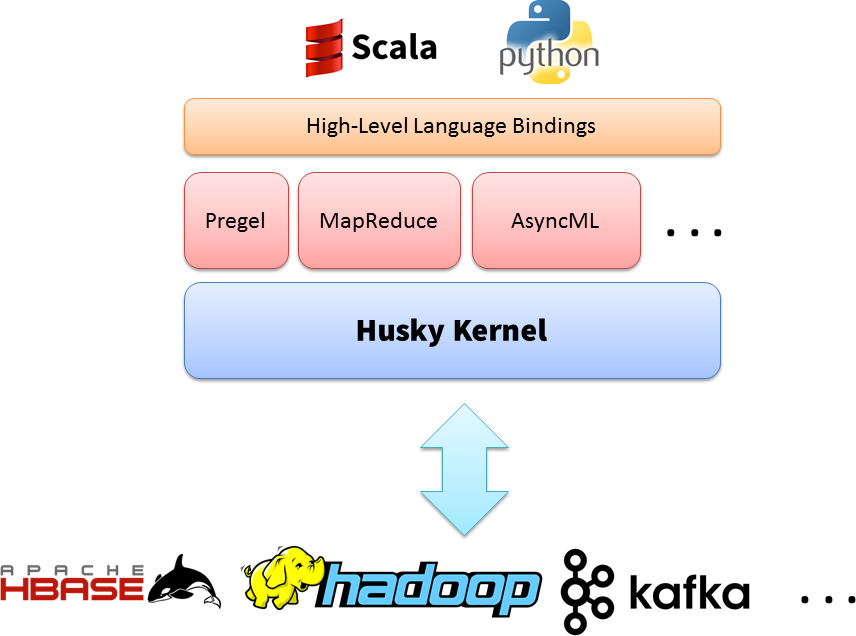
Easy
Easy to learn and use.
Husky exposes an easy-to-use interface, allowing complicated logic to be expressed succinctly.
Husky can easily work with many existing data stores. With the Python/Scala frontends, even non-technical people can get started with Husky quickly, and enjoy all the benefits.
Example 1: Use PyHusky (Husky Python API) to extract a graph from a big json file, compute its PageRank, and get the top k nodes:
import json
import bindings.frontend as ph
import bindings.frontend.library.graph as hg
edgelist = ph.env.load("/path/to/json") \
.map(lambda line:json.loads(line)) \
.map(lambda doc:(doc['src'], doc['dst']))
graph = hg.from_edgelist(edgelist)
graph.pagerank(iter=10)
graph.pagerank_topk(k=2)Example 2: Use ScHusky (Husky Scala API) to solve collaborative filtering with Asynchronous SGD:
import schusky.api._
import schusky.lib.ml._
import play.api.libs.json._
val env = new Environment()
val data = env.mongodb("mongohost", 9000).load("db.collection").map { doc =>
val js = Json.parse(doc)
((js\"user").as[Int], (js\"item").as[Int], (js\"rating").as[Double])
}
val model = Homad.from(Matrix.fromTriplet(data))
model.setReg(0.01).setLearningRate(0.1).mfasync(time=20)
println(model.getRMSE)