Spark
Introduction
Apache Spark is an open-source cluster computing framework originally developed in the AMPLab at UC Berkeley. In contrast to Hadoop's two-stage disk-based MapReduce paradigm, Spark's in-memory primitives provide performance up to 100 times faster for certain applications.
In this lab, we will teach you
- How to interact with Spark using the command line interface spark-shell.
- Write self-contained applications.
Interactive Analysis with the Spark Shell
Spark's shell provides a simple way to learn the API, as well as a powerful tool to analyze data interactively.
a. For the students who are using the VM image which provided before, you can start it by running the following command:
~/Programs/spark/bin/spark-shell
b. For the students who are using their own device (non-windows devices such as Linux, Mac or Cygwin), you can download Spark from here. Unzip the downloaded package and then execute command:
{Unzipped spark folder}/bin/spark-shell
Spark's primary abstraction is a distributed collection of items called a Resilient Distributed Dataset (RDD). RDDs can be created from Hadoop InputFormats (such as HDFS files) or by transforming other RDDs. Let's make a new RDD from the text of the README file in the Spark source directory. We will use the singleton object "sc" (SparkContext) provided by spark-shell to read the file using the function "textFile", which returns an Array contains each line of the file.
scala> val textFile=sc.textFile("/home/bigdata/Programs/spark/README.md")
textFile: org.apache.spark.rdd.RDD[String] = MapPartitionsRDD[1] at textFile at <console>:21
RDDs have 2 types of operations:
- actions, which return values
- transformations, which return pointers to new RDDs.
Let's start 2 simple actions.
- count: return the total number of elements in the RDD
- first: return the first element of the RDD
scala> textFile.count // Number if items in this RDD res0: Long = 95
Now let's use a transformation. We will use the filter transformation to return a new RDD with a subset of the items in the file.
scala> val linesWithSpark = textFile.filter(line => line.contains("Spark"))
linesWithSpark: org.apache.spark.rdd.RDD[String] = MapPartitionsRDD[2] at filter at <console>:29
We can chain together transformations and actions, for exmaple filter and count
scala> textFile.filter(line => line.contains("Spark")).count // How many lines contain "Spark"?
res1: Long = 17
One common data flow pattern is MapReduce, as popularized by Hadoop. Spark can implement MapReduce flows easily. For example, we want to implement a word count in Spark.
- We first transform the text file to an array of words using the flatMap function. In Hadoop MapReduce, it only has a map operator that is 1-to-(0:N) mapping. Recent frameworks like Spark distinguish between:
- map, a strict 1-to-1 mapping (i.e., 1 input tuple t,
return exactly one output tuple t')
- flatmap, 1-to-(0:N) mapping (the example below takes
1 line as input and output a sequence of tokens)
- We can take a glimpse of its result by calling the collect function.
scala> val wordArray = textFile.flatMap(line => line.split(" ")) //Transform the text file to an array of words
wordArray: org.apache.spark.rdd.RDD[String] = MapPartitionsRDD[4] at flatMap at <console>:29
scala> wordArray.collect
res2: Array[String] = Array(#, Apache, Spark, "", Spark, is, a, fast, and, general, cluster, computing, system, for, Big, Data., It, provides, high-level, APIs, in, Scala,, Java,, Python,, and, R,, and, an, optimized, engine, that, supports, general, computation, graphs, for, data, analysis., It, also, supports, a, rich, set, of, higher-level, tools, including, Spark, SQL, for, SQL, and, DataFrames,, MLlib, for, machine, learning,, GraphX, for, graph, processing,, and, Spark, Streaming, for, stream, processing., "", <http://spark.apache.org/>, "", "", ##, Online, Documentation, "", You, can, find, the, latest, Spark, documentation,, including, a, programming, guide,, on, the, [project, web, page](http://spark.apache.org/documentation.html), and, [project, wiki](https://cwiki.apache.org/...
- Then, for each word, we emit a pair (word, 1).
scala> val wordcountPairs = wordArray.map(word => (word,1))
wordcountPairs: org.apache.spark.rdd.RDD[(String, Int)] = MapPartitionsRDD[7] at map at <console>:31
scala> wordcountPairs.collect
res5: Array[(String, Int)] = Array((#,1), (Apache,1), (Spark,1), ("",1), (Spark,1), (is,1), (a,1), (fast,1), (and,1), (general,1), (cluster,1), (computing,1), (system,1), (for,1), (Big,1), (Data.,1), (It,1), (provides,1), (high-level,1), (APIs,1), (in,1), (Scala,,1), (Java,,1), (Python,,1), (and,1), (R,,1), (and,1), (an,1), (optimized,1), (engine,1), (that,1), (supports,1), (general,1), (computation,1), (graphs,1), (for,1), (data,1), (analysis.,1), (It,1), (also,1), (supports,1), (a,1), (rich,1), (set,1), (of,1), (higher-level,1), (tools,1), (including,1), (Spark,1), (SQL,1), (for,1), (SQL,1), (and,1), (DataFrames,,1), (MLlib,1), (for,1), (machine,1), (learning,,1), (GraphX,1), (for,1), (graph,1), (processing,,1), (and,1), (Spark,1), (Streaming,1), (for,1), (stream,1), (processing.,1), ...
- Finally, we reduce all the pairs using the "word" as the key and sum up its count.
scala> val wordcounts = wordcountPairs.reduceByKey((x,y) => x+y)
wordcounts: org.apache.spark.rdd.RDD[(String, Int)] = ShuffledRDD[8] at reduceByKey at <console>:33
scala> wordcounts.collect
res6: Array[(String, Int)] = Array((package,1), (For,2), (Programs,1), (processing.,1), (Because,1), (The,1), (cluster.,1), (its,1), ([run,1), (APIs,1), (have,1), (Try,1), (computation,1), (through,1), (several,1), (This,2), (graph,1), (Hive,2), (storage,1), (["Specifying,1), (To,2), (page](http://spark.apache.org/documentation.html),1), (Once,1), ("yarn",1), (prefer,1), (SparkPi,2), (engine,1), (version,1), (file,1), (documentation,,1), (processing,,1), (the,21), (are,1), (systems.,1), (params,1), (not,1), (different,1), (refer,2), (Interactive,2), (R,,1), (given.,1), (if,4), (build,3), (when,1), (be,2), (Tests,1), (Apache,1), (./bin/run-example,2), (programs,,1), (including,3), (Spark.,1), (package.,1), (1000).count(),1), (Versions,1), (HDFS,1), (Data.,1), (>>>,1), (programming,1), (T...
Mini-exercise
Continue with above example:
Task description: Obtain the common words appear in files "README.md" and file "NOTICE". Since we already have the word of arrays in "README.md" (i.e., the "wordArray"), we only need to process the file "NOTICE".
- Step 1): Create another RDD by "sc" that reads a local file "NOTICE" //hint: using "sc.textFile(...)" method
- Step 2): Transform the text file to an array of words //hint: using the transformation "flatMap"
- Step 3): Use the transformation "intersection" to obtain the common words
|
Reference Solution: Step 1): val rddFile = sc.textFile("NOTICE") Step 2): val wordArray2 = rddFile.flatMap(line => line.split(" ")) Step 3): val commonWord = wordArray.intersection(wordArray2) |
Writing and running Spark program
Now say we wanted to write a self-contained application using the Spark API. We will walk through a simple application in Scala. First, import the project provided in our lab material.
- Download the material used in this lab here. Then, unzip the file.
- Import the project in Eclipse.
- (Optional) If you are using your own device, you need to fix the path of Spark JAR.
- On the left menu "Project Explorer", right click project "SparkExample", and then select "Properties
-
On the left menu of the popup window, click "Java Build Path" and then select the tab
"Library".
A list of library will be shown
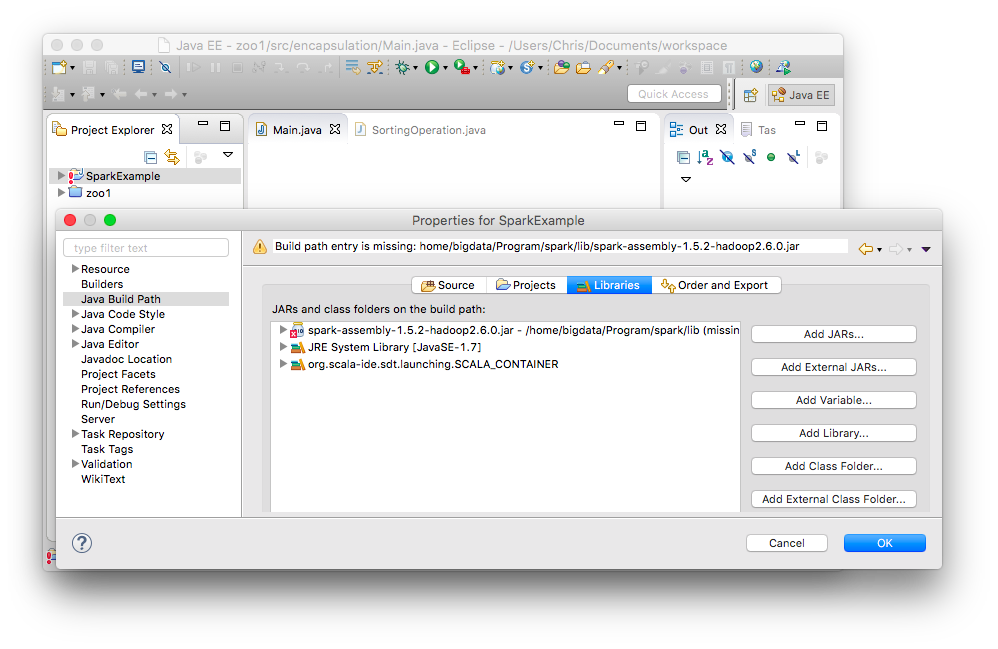
- Click the button "Add External JARs", browse the JAR "spark-assembly-1.6.0-hadoop2.6.0.jar" in "{Unzipped spark folder}/lib"
- Click "OK" to apply the changes
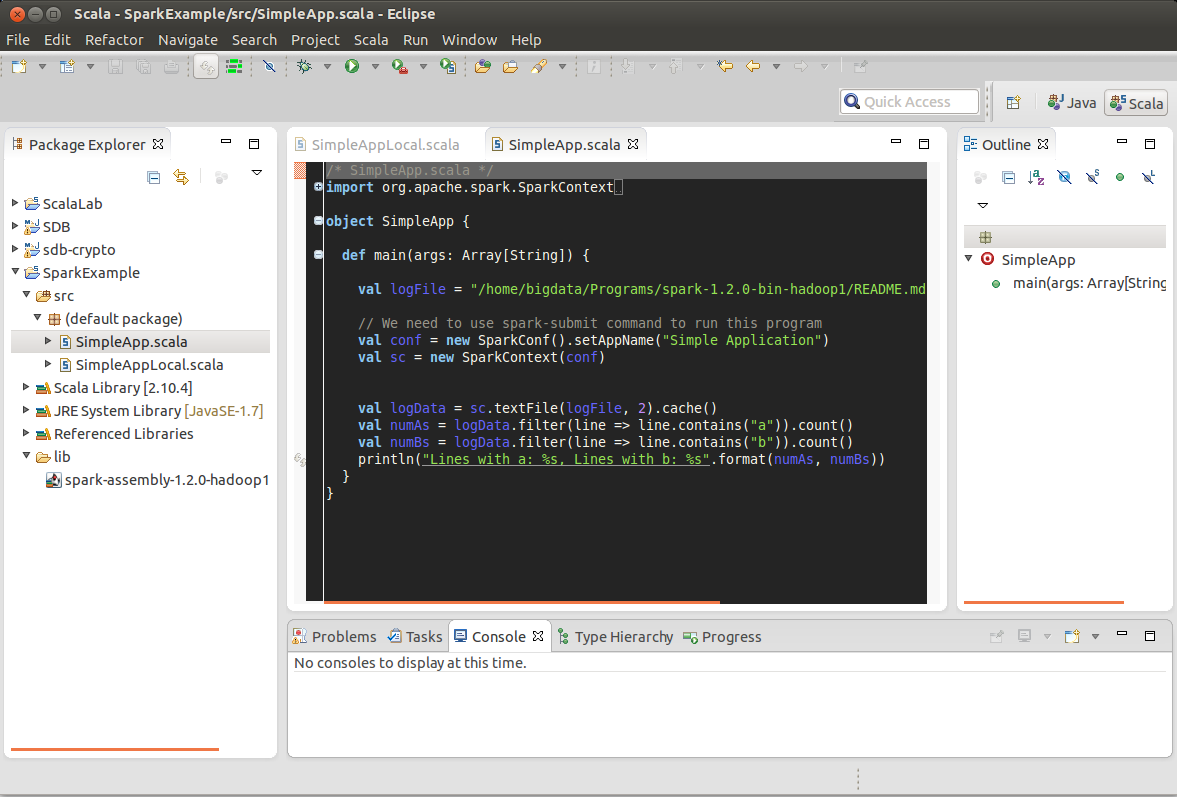
There are two ways to run a Spark application:
- Run it locally (For testing)
- Run it in the cluster (For production)
Run in local mode
 on the toolbar
on the toolbar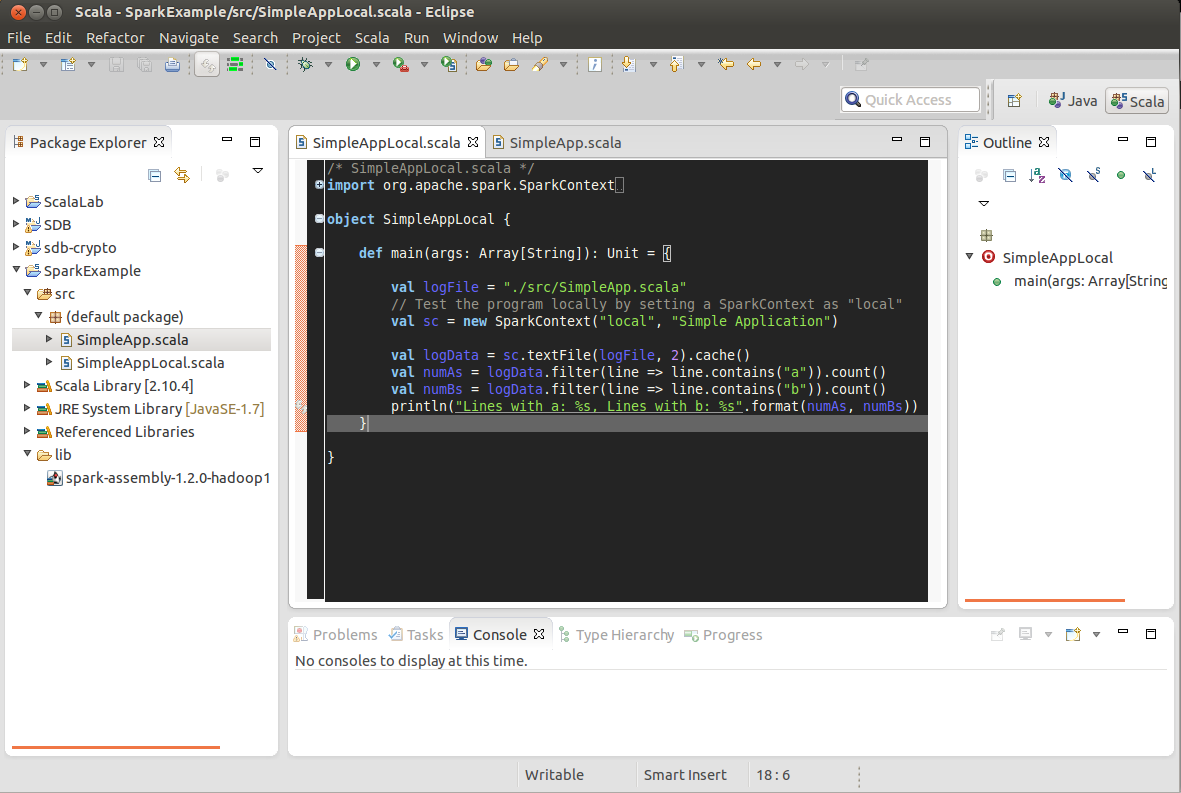
The program output should be display in the "Console" tab which located in the bottom part of Eclipse
Run Spark application in the cluster
Start Spark in cluster mode
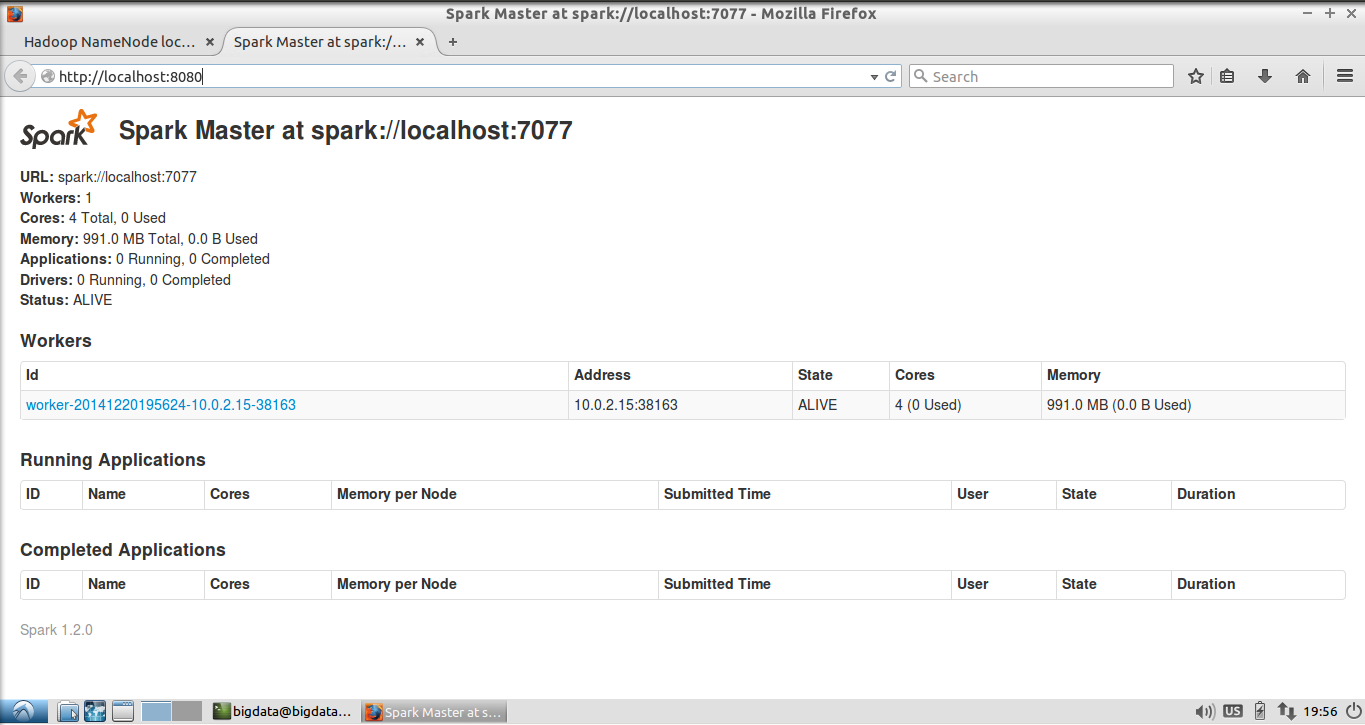
Before execute any spark program. A spark cluster should be configurared and started properly. A complete spark cluster consists of a master nodes and at least on worker nodes. For the details of configuring a spark cluster, please refer to spark official documentation
In the VM image provided, a spark cluster is already configured. You can start the spark cluster by running the following command:
~/Programs/spark/sbin/start-all.sh
To check whether the spark cluster is launched successfully, open Spark's WebUI by browsing this webpage: http://localhost:8080 in the virtual machine. You should see the web page similar to the screenshot below.
Packing a spark program to a JAR
Export the classes as a JAR file to the shared folder.
- Choose "Files" -> "Export..." in the menu bar.
- Choose "Java" -> "JAR file".
- Click Next.
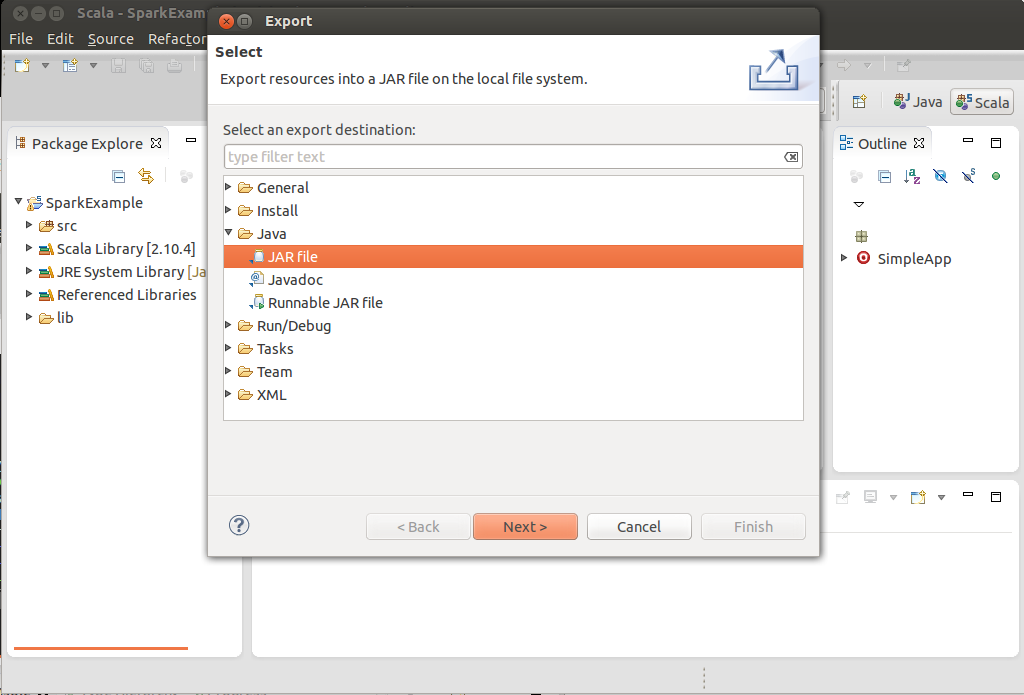
Export the classes as a JAR file.
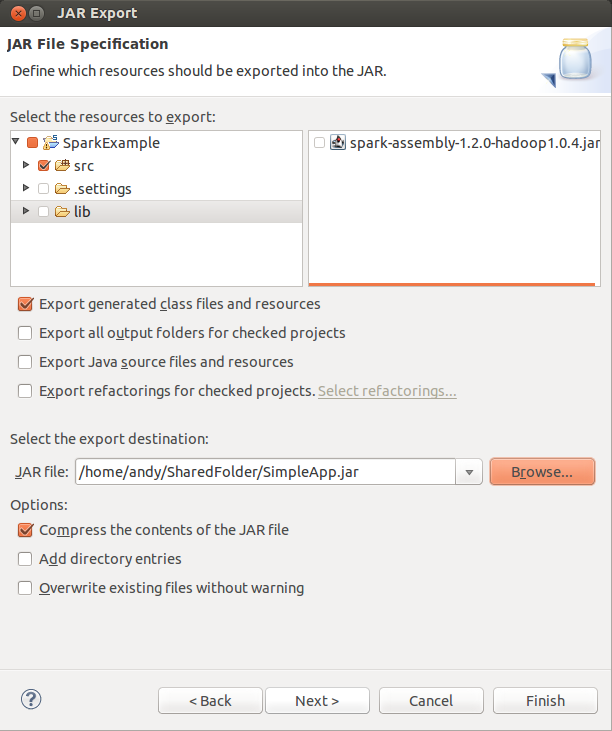
- Choose Select SparkExample
- Uncheck "lib".
- Under "Select the export destination", enter a path to store the exported JAR (e.g. /home/bigdata/SimpleApp.jar)
- Click "Finish".
Execute the spark program on the spark cluster.
Assume you have exported the JAR to /home/bigdata/SimpleApp.jar, you can execute the spark program by using the "spark-submit" command and the exported JAR :
~/Programs/spark/bin/spark-submit --class "SimpleApp" --master spark://localhost:7077 /home/bigdata/SimpleApp.jar