Spark Streaming
Introduction
Why We Need Streaming Analytics
As we all know, more and more companies are wanting to get value from data, of which real-time data counts much. Real-time data processing and analytics allows a company the ability to take immediate action for those times when acting within seconds or minutes is significant. The goal is to obtain the insight required to act prudently at the right time - which increasingly means immediately. So it is different from batch-data processing which is generally more concerned with throughput than latency. In our lives, sensors, IoT devices, social networks, and online transactions are all generating data that needs to be monitored constantly and acted upon quickly. As a result, the need for large scale, real-time stream processing is more evident than ever before.
What is Spark Streaming
Spark Streaming leverages Spark Core's fast scheduling capability to perform streaming analytics. It ingests data in mini-batches and performs RDD transformations on those mini-batches of data. This design enables the same set of application code written for batch analytics to be used in streaming analytics, on a single engine.
Why Spark Streaming
Before Spark Streaming, building complex work that encompass streaming, batch, or even machine learning capabilities with open source software meant dealing with multiple frameworks, each built for a niche purpose, such as Storm for real-time actions, Hadoop MapReduce for batch processing, etc. Besides the pain of developing with disparate programming models, there was a huge cost of managing multiple frameworks in production. Spark and Spark Streaming, with its unified programming model and processing engine, makes all of this very simple.
In this lab, we will give an example that helps you learn processing Twitter's real-time sample streams by Spark Streaming. Background of Scala language is a must.
Start From Here
Get Ready
- Download materials for this lab here and unzip it.
- Import the project into Eclipse and set "java build path" by adding all external jars in folder "lib".
Go Through the Example
Because this tutorial is based on Twitter's sample tweet stream, we need to configure its OAuth authentication with a Twitter account. In this lab, TA provides and hard-coded temporary access keys in TwitterPopularTags.scala, and these keys are set to system's properties as below
System.setProperty("twitter4j.oauth.consumerKey", consumerKey)
System.setProperty("twitter4j.oauth.consumerSecret", consumerSecret)
System.setProperty("twitter4j.oauth.accessToken", accessToken)
System.setProperty("twitter4j.oauth.accessTokenSecret", accessTokenSecret)
A kind reminder: the keys provided in TwitterPopularTags.scala of this tutorial are to expire on 2/MAY/2016. Please generate authentication with your own twitter account following this and replace them then.
Now we create a StreamingContext, the main entry point for all Spark Streaming functionality, with batch interval of 2 seconds.
val sparkConf = new SparkConf().setAppName("TwitterPopularTags")
val ssc = new StreamingContext(sparkConf, Seconds(2))
Using this context ssc, we can define the input source by creating a Discretized Streams (DStream), which represents streaming data from Twitter, by TwitterUtils.createStream. A DStream, the basic abstraction in Spark Streaming, is a continuous sequence of RDDs (of the same type) representing a continuous stream of data
val stream = TwitterUtils.createStream(ssc,None)
Each record in this stream is a line of text. Similar to that of RDDs, transformation allow the data from the input DStream to be modified. DStreams support many of the transformations as we are familiar with normal Spark RDD's, such as flatMap
//Split each line into words that are separated by blank-space, and get hash tags
val hashTags = stream.flatMap(status => status.getText.split(" ").filter(_.startsWith("#")))
Spark Streaming also provides windowed computations, by which we can apply transformations over a sliding window of data. Find detailed illustrations about windowed computations here
val topCounts60 = hashTags.map((_, 1)).reduceByKeyAndWindow(_ + _, Seconds(10)) // window-length = 10s
.map{case (topic, count) => (count, topic)}
.transform(_.sortByKey(false)) // sort the count in descending order
Note that until now, Spark Streaming only sets up the computation "framework" it will takes, however no real processing has triggered yet. To start receiving data and relevant computations, we need to call start() on StreamingContext. Then the data will be received from Twitter Streaming API, transformed and output according to previous computation steps continuously.
ssc.start() //start the computation ssc.awaitTermination() //wait for the computation to terminate
Run the Program
As we have learned how to run Spark application in the cluster previously, it is similar to run the program here
- Packing the Spark program to a JAR
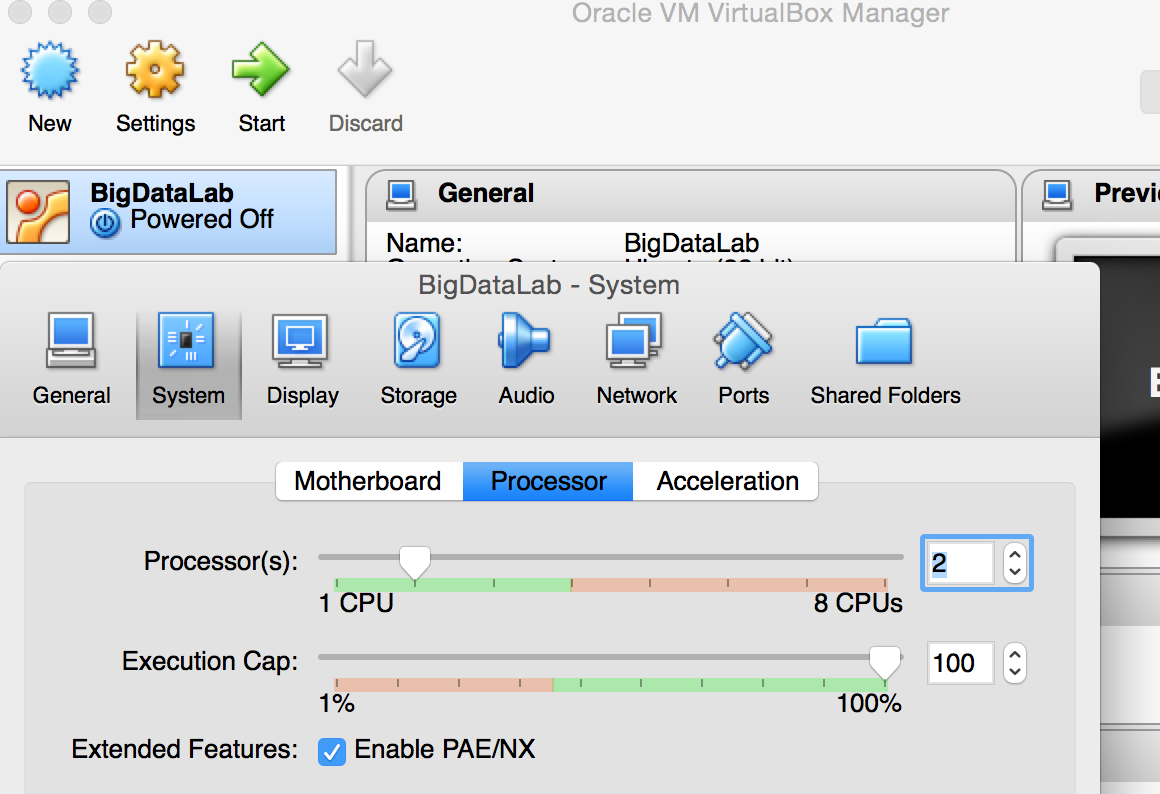
- To ensure the program works in our VM environment, please reset the number of processors to 2 (more than 1). Click "Setting" :
- Execute the Spark program on the spark cluster, using
spark-submitwith--jarsparameter to state out external jars. For example:
./bin/spark-submit --class polyu.bigdata.TwitterPopularTags --master spark://localhost:7077 --jars /home/bigdata/spark-streaming-twitter_2.10-1.6.0.jar,/home/bigdata/twitter4j-stream-4.0.4.jar,/home/bigdata/twitter4j-core-4.0.4.jar /home/bigdata/SparkStreamingExample.jar
The output looks like
Popular topics in last 10 seconds (128 total): #KCA (13 tweets) #MiHumorCambiaCuando (5 tweets) #EXO (3 tweets) #osomatsusan (2 tweets) #bokep (2 tweets) #ThrowbackThursdayTHATSMYBAE (2 tweets) #Vote5H (2 tweets) #VoteEnriqueFPP (2 tweets) #SiTeAmaEntonces (2 tweets) #bispak (2 tweets)
Look Back
Now let's rethink the whole process after going through the above example, from the view of external dependencies of this program.
spark-assembly-1.6.0-hadoop2.6.0.jar: we are familiar with this one that is essential to build Spark program.spark-streaming-twitter_2.10-1.6.0.jar:Spark Streaming utilizes this to ingest data from Twitter source. We add this as external jar because Twitter is not present in the Spark Streaming core API, which meansspark-assembly-1.6.0-hadoop2.6.0.jarcan not cover this.twitter4j-core-4.0.4.jarandtwitter4j-stream-4.0.4.jar: these two provides Java library for the Twitter API.
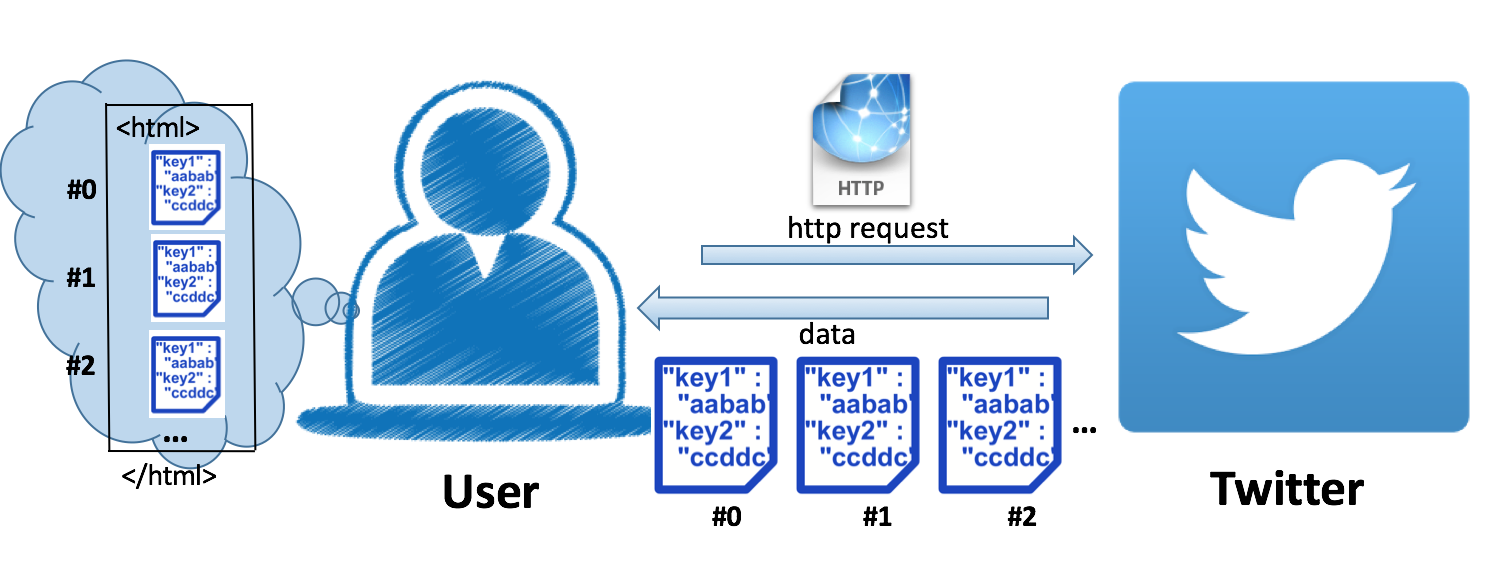
That is, we get identification of Twitter applications by OAuth, which is provided by twitter4j-core-4.0.4.jar, and make request to Twitter's Streaming APIs. Twitter responses and sends a sequence of "data" back continuously and each "data" is JSON encoded: we could imagine this process as retrieving a very-long(never-ending) html file from the web server.
Spark ingests the data using functionalities provided by spark-streaming-twitter_2.10-1.6.0.jar into DStream, and finally we use Spark Streaming (included in Spark) to operate DStream.
Mini-exercise
- Print ten tweets in every 2 seconds. Hint: output operations on DStreams.
- Print top-5 hashtags in the last 60 seconds in every 30 seconds. Hint: transformations on DStream.
|
Reference Solution: Question 1): val statuses = stream.map(status => status.getText()) statuses.print() Question 2): val topCounts60 = hashTags.map((_, 1)).reduceByKeyAndWindow((a:Int,b:Int) = >a+b, Seconds(60),Seconds(30)).map{case (topic, count) => (count, topic)}.transform(_.sortByKey(false)) topCounts60.foreachRDD(rdd => { val topList = rdd.take(5) println("\nPopular topics in last 60 seconds (%s total):".format(rdd.count())) topList.foreach{case (count, tag) => println("%s (%s tweets)".format(tag, count))} }) |