Spark SQL is Spark's module for working with structured and semi-structured data. It allows relational queries expressed in SQL to be executed using Spark.
As we know before, Spark's primary abstraction is a distributed collection of items called Resilient Distributed Dataset (RDD). In order to make data queriable with SQL in Spark, data need to be represented in a new type of RDD, SchemaRDD.
In this lab, we will teach you
These steps will be illustrated using Spark's command line interface spark-shell.
JDK8 is necessary for Spark SQL. You can download the compressed JDK files through the web browser in the guest OS without using the shared folder, and extract it:
Move the extracted folder to /usr/lib/jvm and install JDK8:





Switch the Java/Javac version to the latest version (by entering the number of the first column):
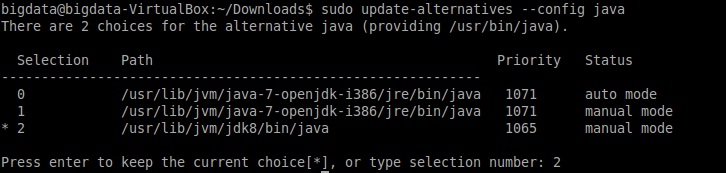
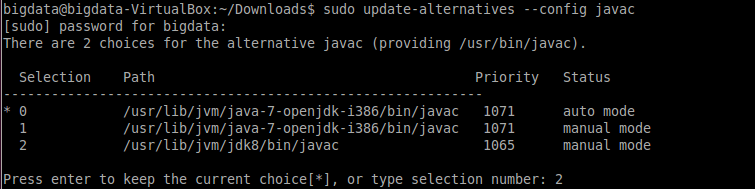
To see whether JDK8 is installed successfully:

Since Spark is implemented on top of HDFS, we need to start HDFS before launching Spark.
Open the terminal. Navigate to the home directory of hadoop by the following command:

Start HDFS by the following command:

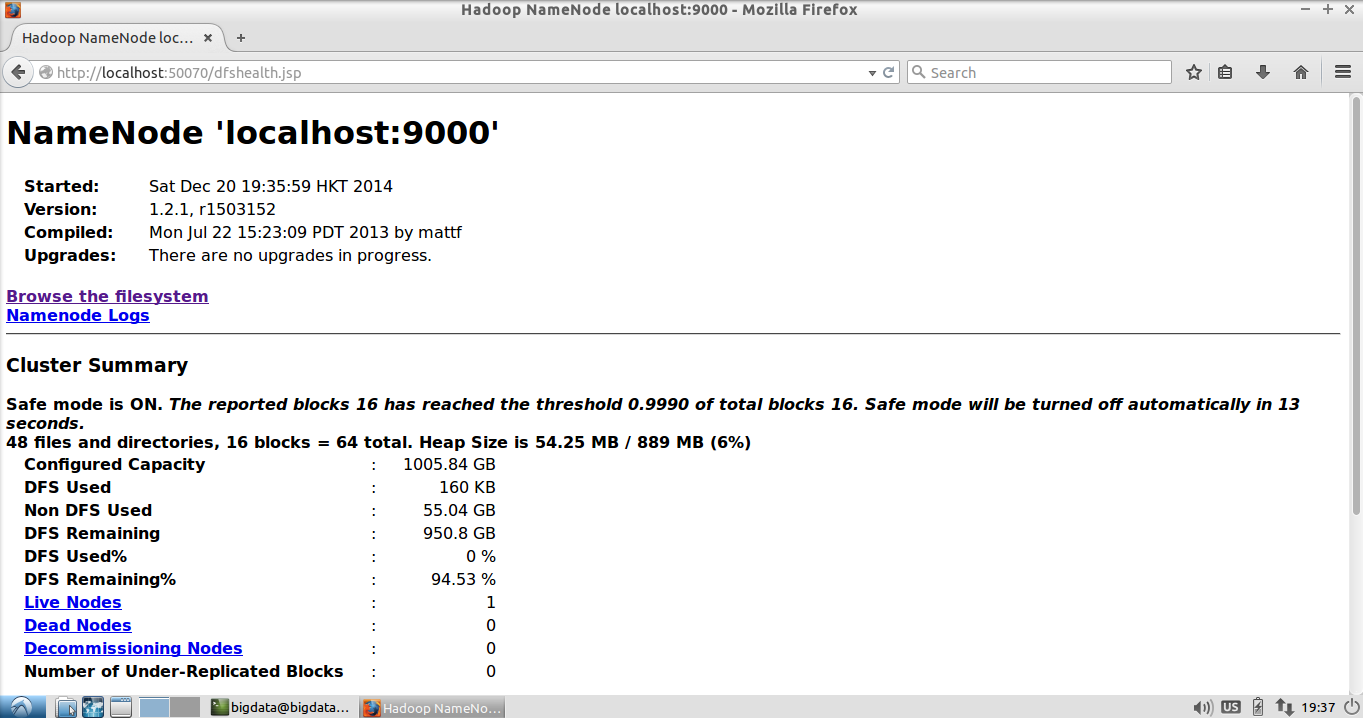
Open HDFS's WebUI address: http://localhost:50070 in the virtual machine to see if HDFS has started successfully.
Next, we need to upload all input data to HDFS such that the data can be distributed across the cluster.
Send the input files (product.txt and companies.json) to the virtual machine through shared folder.

Create a folder in the HDFS, and upload the input files to that folder:

We can see the uploaded files through HDFS's WebUI:
Navigate to the home directory of Spark by the following command:
Start Spark by the following command:

Open Spark's WebUI address: localhost:8080 in the virtual machine to see if Spark has started successfully.
Finally, we start Spark-shell by running the following command in the Spark directory:

In this part, we will show you how to query relational data using SparkSQL.
The SQLContext class is the entry point to all relational functionalities in Spark. To create that, we use the variable sc (system build-in SparkContext object):

We create an RDD from the input text file product.txt:

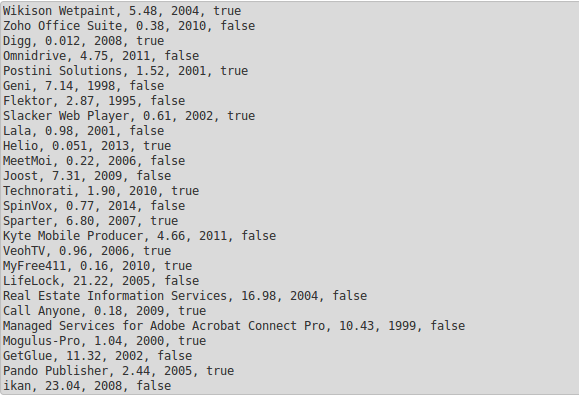
As illustration, we show the text file below. In productRDD, each element is a single line of this text file.
Since different users/applications may be interested in different portion of the data, we create the schema represented by a StructType on the runtime (i.e., schema-on-read):

Then, we conduct the ETL (Extract, Transform, Load) process on the RDD (i.e., productRDD), and attach the schema to it:

After we register the SchemaRDD as a table, we are able to run SQL queries over it:

Assume that another application is interested in columns "name", "revenue", and "release_year" (i.e., the third column) of the product dataset.
Please attach a new schema to the dataset and issue a query to get the five latest released products whose revenue is larger than 10 million dollars.
|
Reference SQL: SELECT * FROM product WHERE revenue > 10 ORDER BY release_year DESC LIMIT 5 |
In this part, we will show you how to query JSON data using SparkSQL. We continue the shell and re-use the sqlContext.
jsonFile is the method to loads data as a SchemaRDD from a JSON file (or a directory of JSON files) where each line of the files is a JSON object:

As illustration, we show two lines of companies.json; we also demonstrate respective JSON data with proper indentation and line feeds:
[Line 1:]


[Line 2:]

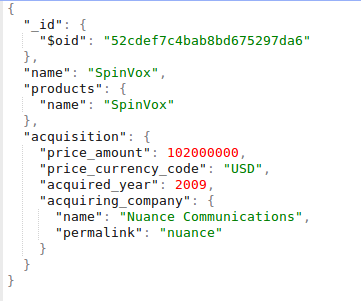
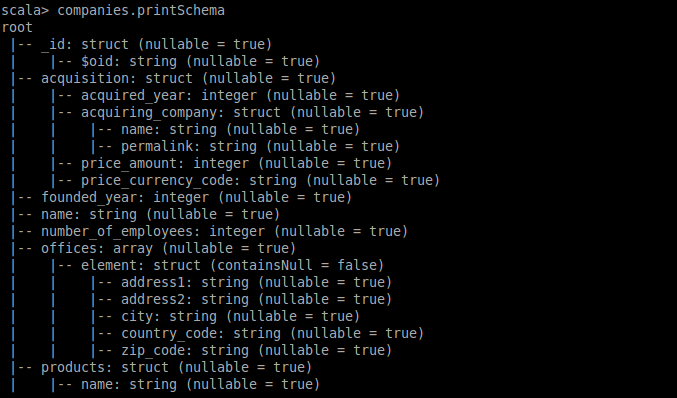
By parsing/loading the JSON dataset, SparkSQL can automatically infer its schema. See the result of printSchema():
Similarly, we register the SchemaRDD as a table named company and conduct queries over it:


So we can access any nested attribute according to the schema. Also, as we can see in the previous JSON object examples, the company Livestream does not have the attribute acquisition.pricing_amount, so it returns a null value for that attribute.
As another interesting example, we want to see whether null value is counted in aggregation:

The conclusion is that, null value is not counted in calculating the average amount of acquiring price ((6.25E8 + 0.2E8 + 0.39E8) / 3 = 2.28E8).
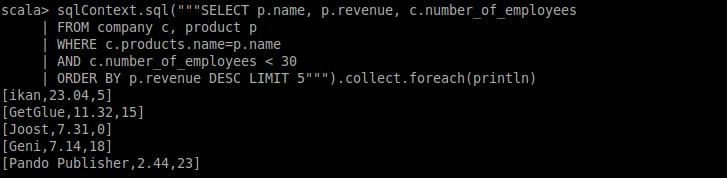
Since we have registered both temporary tables (i.e., product and company), and they have a unified access interface (i.e., SchemaRDD), we can query them (i.e., data from two sources/structures) if they can be integrated.
Now, assume that (i) the name of products in the table product and (ii) the name of products saled by companies in the table company are in the same domain. Under this assumption, we can join this two tables with the following query: