Quegel Architecture Overview
Quegel Architecture
A diagram of the architecture of Quegel is shown in the figure below, where users may pose graph queries to a server program through Quegel client programs. Quegel is implemented in C/C++ as a group of header files, and to write a server-side program, users only need to include the necessary base classes and implement the query processing logic in their subclasses. A Quegel server program is compiled using GCC, preferably with -O2 option enabled. Click here to see how to run a Quegel program in your cluster.
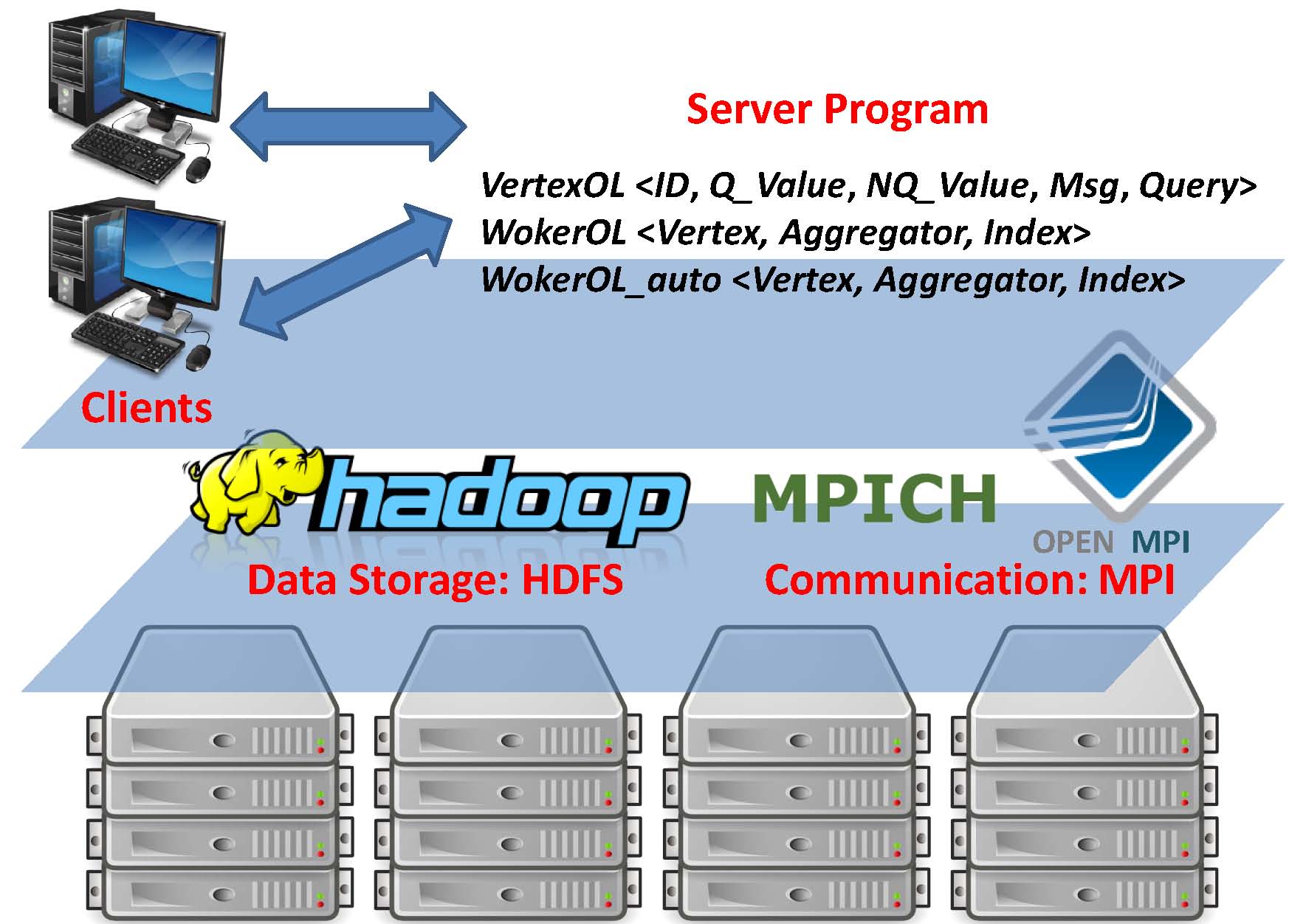
Quegel communicates with HDFS (e.g. for graph loading, and dumping query results) through libhdfs, a JNI based C API for HDFS. Each computing unit (or, worker) of Quegel is simply an MPI process and communications are implemented using MPI communication primitives. One may deploy Quegel with any Hadoop and MPI version, such as Hadoop 1.2.1 and MPICH 3.0.4.
User-Defined Classes
In this web page, we just provide a high-level description of Quegel's base classes. Users need to subclass them with their template arguments properly specified in the server application code. Click here to check the detailed programming interface.
We remark that the system code also includes the base classes of Pregel+ and Blogel, which are useful, for example, to preprocessing graph data or to build graph index offline. For the usage of these classes, please refer to the respective system websites.
VertexOL
The VertexOL class is like the vertex class of Pregel. It has two abstract functions: (1) UDF (user-defined function) init_value(q), where users specify what value should be initialized to a vertex v, if v is visited by a query q for the first time. Note that to be space-efficient, Quegel only allocates state to a vertex v for a query q if v is visited by q. (2) UDF compute(msgs), where users implement their vertex-centric query processing logic. A VertexOL object maintains three fields: a vertex ID of type <ID>, a query-independent vertex value of type <NQ_Value> (e.g., to store adjacency list or static labels), and a table that maintains the vertex state for every query that has visited the current vertex. The vertex state of a vertex v for a query q maintains (i) a boolean state indicating whether v is active for q, (ii) a query-dependent value of type <Q_Value>, and (iii) an incoming message queue to collect those messages destined to v in query q. Here, we do not hard code adjacent list data structure for VertexOL, but rather let users specify it with <NQ_Value>. This is more flexible because in some algorithms like bi-directional BFS, we also need to maintain two adjacency lists, one for in-neighbors and the other for out-neighbors; while in other algorithms we do not need the adjacency list at all (e.g. the k-means algorithm of this paper).
WorkerOL
The WorkerOL class takes the user-defined VertexOL subclass (denoted by Vertex) as a template argument, and implements the execution procedure of a worker process of the Quegel server program. It has four formatting abstract functions for users to specify:
Vertex* toVertex(char* line)
Query toQuery(char* line)
void dump(Vertex* v, BufferedWriter& writer)
void save(Vertex* v, BufferedWriter& writer)
The toVertex(line) function defines how to parse a line from the input graph file(s) on HDFS into a vertex object. When a job runs, this function will be called for each line of the input graph file(s), right before graph computation begins. Note that the function returns a pointer, which means that users need to call new Vertex in the function and set its field properly before returning it. We return Vertex * instead of Vertex to avoid the copying of a potentially large vertex object, and vertex deletion is automatically handled by our system.
The toQuery(line) function defines how to parse a query string (sent from a client) into the query content of type <Query>. For example, for point-to-point shortest path queries, <Query> contains the source and destination vertex IDs.
The dump(.) function defines what to write to HDFS (using BufferedWriter& writer) for a processed vertex Vertex* v after a query is answered. When a query q finishes evaluation, this function is called for each vertex visited by q, e.g., to output the query-dependent vertex value. . The save(.) function defines what to write to HDFS for each vertex when the server program exits. Quegel allows a query to update the query-independent vertex values, and so these query-independent vertex values may have been updated by the queries processed and need to be saved to HDFS. The HDFS path to save these data is set by the WorkerOL::set_file2save(path) function.
The WorkerOL class also has an abstract functions to activate some initial vertices at the beginning of a query:
init(vertexes)
Here, vertexes is the array of vertices maintained by the current worker process. Inside init(.), one may call get_vpos(vertexID) to obtain the position of that vertex in vertexes, and then call activate(pos) to activate that vertex using the obtained position.
Finally, Quegel allows a server program to let each worker build a local index over its loaded vertices, to be used during query processing. There are three relevant abstract functions:
idx_init()
load2Idx(line, idx)
load2Idx(v, pos, idx)
WorkerOL_auto
The WorkerOL_auto class is similar to WorkerOL. The only difference is that WorkerOL only supports queries typed by users at the client console, while WorkerOL_auto also accepts batches of queries submitted by users who type the file names of query batches at the client console. See "Preparing the Client-Side Program" of this page for the difference between the two types of clients.
Combiner
We assume users are familiar with the concept of message combiner. Otherwise, you may check Section 3.2 of this paper. Quegel support two modes of combiners. In the normal mode, the Combiner class has only one abstract function for users to specify:
combine(Msg& old_msg, Msg& new_msg)
Here, old_msg refers to the combined message. When a vertex in the current worker sends a message to vertex tgt, the system checks whether it is the first message on this worker targeted at tgt. If so, it becomes old_msg; otherwise, combine(old_msg, new_msg) is called to combine that message (i.e. new_msg) with the combined message (i.e. old_msg).
In some applications, it is not appropriate to aggregate all the messages to the same target vertex tgt into one message. Often, <Msg> has multiple fields, and there is a field <Msg>.key that partitions these messages into groups, and only messages with the same value of <Msg>.key can be combined. To enable this kind of message combining, users need to put #define SECONDARY_KEY_MSG at the beginning our their application code, and formulate the message type with Msg2ndKey<key, val> (defined in "utils/Combiner.h"), where key should be specified with <Msg>.key, and val contains the rest of the message content. Finally, one needs to implement the following abstract function for the Combiner class, indicating how to combine <Msg>.val of messages destined to the same vertex and having the same value of <Msg>.key:
combine(val& old_msg_val, val& new_msg_val)
Aggregator
We assume users are familiar with the concept of aggregator. Otherwise, you may check Section 3.3 of this paper. The Aggregator class has five abstract functions for users to specify:
void init()
void stepPartial(VertexT* v)
void stepFinal(PartialT* p)
PartialT* finishPartial()
FinalT* finishFinal()
We illustrate the usage of the above functions by describing how our aggregator works. Note that each query being processed is associated with one independent aggregator.
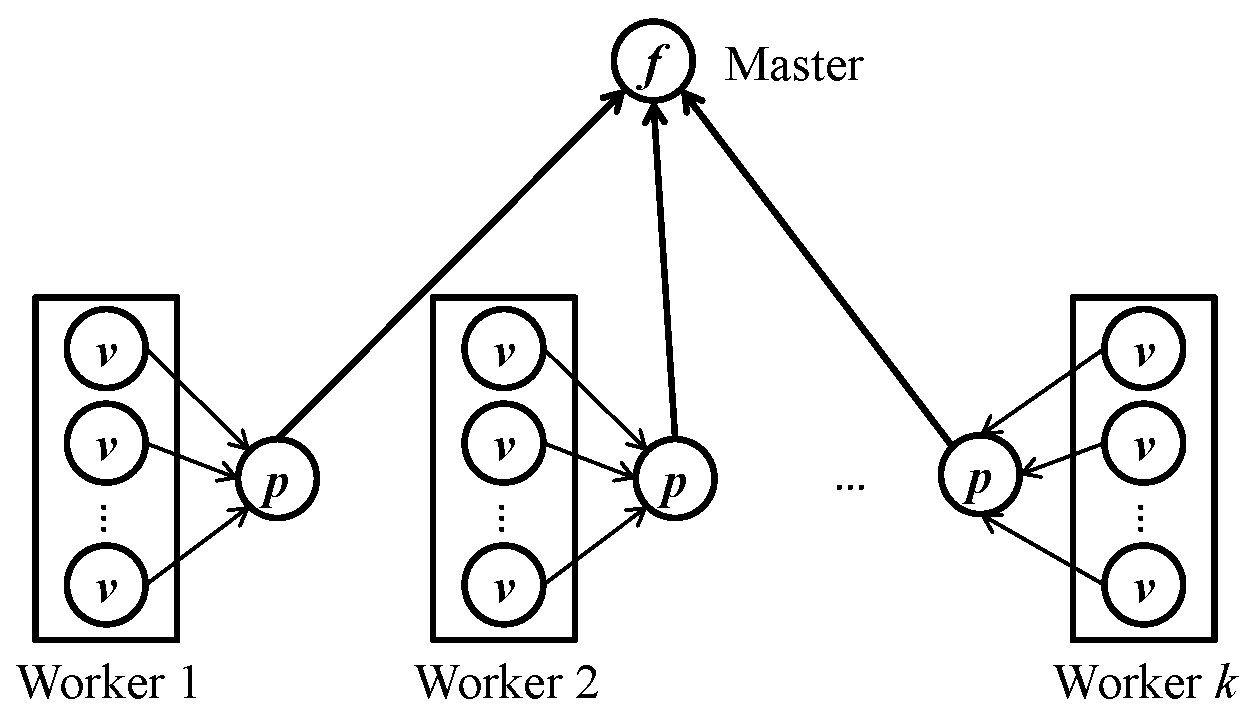
Each worker maintains an aggregator object for each query. At the beginning of a superstep (before vertex-centric computation), the aggregator object calls init() to initialize its state. Then, for each vertex v that is active at the beginning of the superstep, v.compute() is first called, followed by the aggregator calling stepPartial(v). In stepPartial(v), the aggregator checks v's state (which may already be updated by v.compute()) and updates its own state. Note that stepPartial(v) is called as long as v is active at the begnning of the superstep, even when v votes to halt in compute(). After vertex computation finishes, the system calls finishPartial() to obtain the partially aggregated state (of type PartialT) for each worker. This partially aggregated state is presented as the circles marked with p in the above figure.
Before the next superstep begins, the partially aggregated value p of each worker is sent to the master, where the master calls stepFinal(PartialT* p) to update the state of its aggregator with that of p (note that our system makes master also a worker, which processes a fraction of vertices and has its own aggregator object). After stepFinal(PartialT* p) is called for all partially aggregated values, the master calls finishFinal() to obtain the final aggregated value (i.e. the circle marked with f in the above figure) and broadcasts it back to each worker. If one wants to post-process the aggregated result before the next superstep, one may do that in finishFinal() (which is similar to the master-compute functionality of Giraph and GPS).
If you have many vertex states to aggregate (possibly with different logic), you may implement them as the fields of your Aggregator subclass and implement the abstract functions to update them properly.
(De)Serialization
In a distributed system, in order to send a main-memory object to another machine, one needs to define how to map the object into its serial representation (and vice versa). The main-memory object is first serialized to a binary stream, which is sent to the target machine; after receiving the binary stream, the receiving machine deserializes the stream to obtain the main-memory object.
In Java-based systems such as Hadoop and Giraph, this is achieved by the Writable interface. Any type of object that needs to be sent through the network should implement the Writable interface. For example, if an integer needs to be transmitted though the network, one should use IntWritable instead of simply using int.
In Quegel, we are able to decouple the (de)serialization operation from the object type, thanks to C++'s support of operator overloading. Specifically, one may use any data type in their code, and if the data needs to be transmitted over the network, one needs to define the (de)serialization function for its type by overloading the operators << and >>. For example, if we have a type (C/C++ basic data type, struct, or class) T that should be serializable, we define the following two functions:
obinstream& operator>>(obinstream& m, T& data)
ibinstream& operator<<(ibinstream& m, const T& data)
Here, the usage is similar to cout<< and cin>>, except that we are writing binary streams instead of text streams. We were careless during the design and the name obinstream and ibinstream are reversed from their meaning, but we leave them as they are, since revising them involves updating a lot of places throughout the system and application codes. The first function specifies how to serialize data to the input stream m, which is then sent to the target machine. The second function specifies how to deserialize the received output stream m to obtain the object data. After users define the (de)serialization operations, the system knows how to convert T-typed object to/from the serial data streams.
For basic C/C++ data types such as int, double and std::string, users can directly call m<<data and m>>data since they are already defined in utils/serialization.h. Similarly, utils/serialization.h also defines (de)serialization functions for STL containers such as std::vector<T> and __gnu_cxx::hash_map<K, V>. As long as the template argument(s) are serializable, the container type is serializable. For example, one can directly call m<<data for data of type std::vector<int> since int is serializable.
In most cases, the (de)serialization functions are called by the system rather than users. However, one may need to define the (de)serialization functions for user-defined types, where the predefined (de)serialization functions can be used in a recursive manner. For example, suppose that we have a type:
struct my_type
{
int state;
vector<int> out_neighbors;
};
We may define the (de)serialization functions of my_type using the predefined (de)serialization functions of its components as follows:
obinstream& operator>>(obinstream& m, my_type& data)
{
m >> state;
m >> out_neighbors;
return m;
}
ibinstream& operator<<(ibinstream& m, const my_type& data)
{
m << state;
m << out_neighbors;
return m;
}
We now use class VertexOL<ID, Q_Value, NQ_Value, Msg, Query> in ol/VertexOL.h to illustrate what types should be serializable. If the (de)serialization functions are not defined for those types, the application code cannot pass compilation. Firstly, each vertex should be serializable, since after vertices are loaded in parallel by different workers from HDFS, they need to be exchanged though the network, so that finally each worker w only holds those vertices v with hash(v) = w before graph computation. In our system, the user-defined VertexOL subclass is serializable, as long as all its template arguments <ID>, <Q_Value>, <NQ_Value> are serializable, which should be guaranteed by users. Also, since the computation is done by message passing, the message type <Msg> should also be serializable. Finally, if aggregator is used, a partially aggregated value of type PartialT should be serializable since it is sent from a worker to the master though the network; similarly, the final aggregated value of type FinalT should be serializable, since it is broadcast back from the master to all workers though the network.
Communication
All the communication operations are handled by the system itself, and application programmers may safely skip this part. For those who would like to change or extend the system code, we provide more details here.