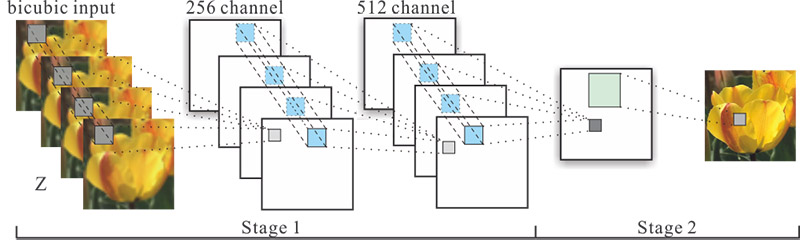
Fig. 1 The two stages of our CNN framework
Renjie Liao1 Xin Tao1 Ruiyu Li1 Ziyang Ma2 Jiaya Jia1
The Chinese Univeristy of Hong Kong 1
University of Chinese Academy of Sciences 2
|
Fig. 1 The two stages of our CNN framework |
Abstract
We propose a new direction for fast video superresolution (VideoSR) via a SR draft ensemble, which is defined as the set of high-resolution patch candidates before final image deconvolution. Our method contains two main components – i.e., SR draft ensemble generation and its optimal reconstruction. The first component is to renovate traditional feedforward reconstruction pipeline and greatly enhance its ability to compute different super-resolution results considering large motion variation and possible errors arising in this process. Then we combine SR drafts through the nonlinear process in a deep convolutional neural network (CNN). We analyze why this framework is proposed and explain its unique advantages compared to previous iterative methods to update different modules in passes. Promising experimental results are shown on natural video sequences.
Downloads
 |
"Video Super-Resolution via Deep Draft-Ensemble Learning" Renjie Liao, Xin Tao, Ruiyu Li, Ziyang Ma, Jiaya Jia IEEE International Conference on Computer Vision (ICCV), 2015 |
Experiments
 |
Fig. 2 Reconstructed blurred high-resolution images with different flow parameters. The 1st row ans 2nd row show the results of TV-L1 flow [1] and MDP flow [2] respectively. |
Results
 |
|||
| (a) Bicubic | (b) Results of [3] | (c) Our results | (d) Ground truth |
| Fig. 3 Comparison of synthetic sequences at a magnification factor of 4. | |||
 |
 |
 |
|---|---|---|
| Click buttons to show results made by different algorithms | ||
| Fig. 4 Comparison on real natural sequences at a magnification factor of 4. Note that due to different implementation details, there exists pixel shift in results of Fast Video Upsampling and Video Enhancer. | ||
Related Projects
References
[1] T. Brox, A. Bruhn, N. Papenberg, and J. Weickert. High accuracy optical flow estimation based on a theory for warping. In ECCV, pages 25–36, 2004.
[2] L. Xu, J. Jia, and Y. Matsushita. Motion detail preserving optical flow estimation. IEEE TPAMI, 34(9): 1744–1757, 2012.
[3] C. Liu and D. Sun. On bayesian adaptive video super resolution. IEEE TPAMI, 2013.
[4] H. Takeda, P. Milanfar, M. Protter, and M. Elad. Superresolution without explicit subpixel motion estimation. IEEE TIP, 18(9): 1958–1975, 2009.
[5] Q. Shan, Z. Li, J. Jia, and C.-K. Tang. Fast image/video upsampling. ACM TOG, 27(5): 153, 2008.
[6] Video Enhancer. http://www.infognition.com/videoenhancer/, 2010.