Blogel Architecture Overview
Blogel Architecture
A diagram of the architecture of Blogel is shown in the figure below. Blogel is implemented in C/C++ as a group of header files, and users only need to include the necessary base classes and implement the application logic in their subclasses. A Blogel application program is compiled using GCC, preferably with -O2 option enabled. Click here to see how to run a Blogel program in your cluster.
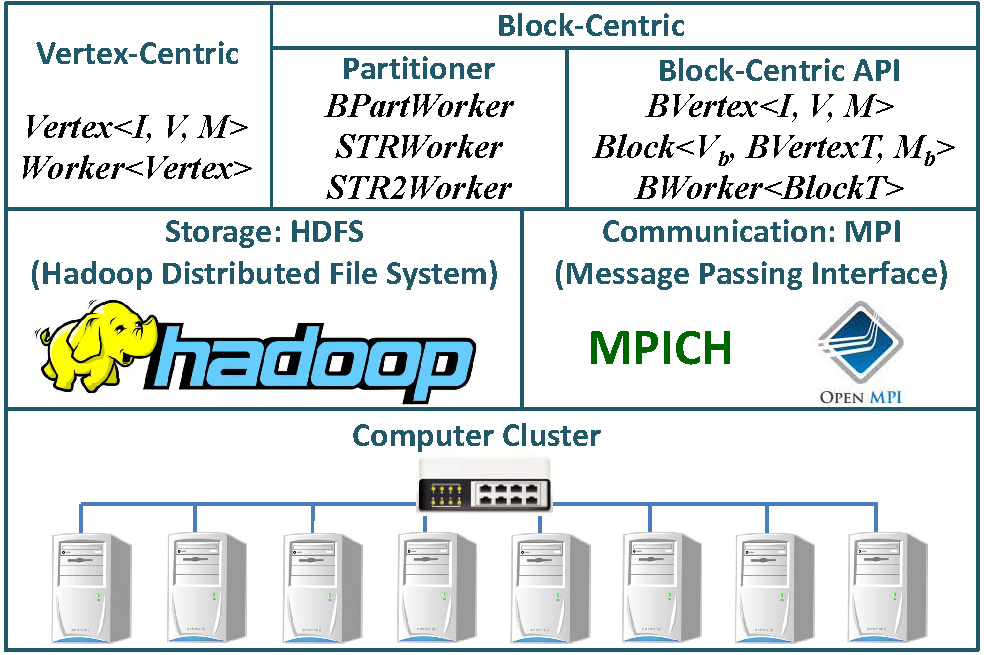
Blogel communicates with HDFS (e.g. for graph loading and result dumping) through libhdfs, a JNI based C API for HDFS. Each computing unit (or, worker) of Blogel is simply an MPI process and communications are implemented using MPI communication primitives. One may deploy Blogel with any Hadoop and MPI version, such as Hadoop 1.2.1 and MPICH 3.0.4. Unlike Pregel, Blogel also makes the master a worker. Since a Blogel job usually runs very fast, the current Blogel version relies on the data replication in HDFS for fault-tolerance, and one may simply re-run a job if it fails due to the breakdown of a machine.
User-Defined Classes
In this web page, we just provide a high-level description of Blogel's base classes. Users need to subclass them with their template arguments properly specified in the application code. Click here to check the detailed programming interface.
Part I: Vertex-Centric Computation
Vertex
The Vertex class has an abstract compute() function, where users implement their vertex-centric computing logic. An Vertex object maintains three fields: a vertex ID of type <I>, a vertex value type <V>, and a boolean state indicating whether it is active. Unlike other Pregel-like systems where a vertex object also maintains an adjacency list of items representing the out-edges with value type <E>, we choose to let users implement the adjacent list(s) in <V>. This is because in some algorithms like bi-directional BFS, we also need to maintain the in-neighbors, while in other algorithms we do not need the adjacency list at all (e.g. the k-means algorithm of this paper). Moreover, while <E> is required to indicate the edge length for weighted graphs, it is useless for unweighted graphs, and the adjacency list can be simply implemented as std::vector<I> to save space. In this sense, our approach is more flexible.
Worker
The Worker class takes the user-defined Vertex subclass as an argument, and has two abstract functions for users to specify:
VertexT* toVertex(char* line)
void toline(VertexT* v, BufferedWriter& writer)
The first function defines how to parse a line from the input graph data on HDFS into a vertex object. When a job runs, this function will be called for each line of the input graph data, before graph computation begins. Note that the function returns a pointer, which means that users need to call new VertexT in the function and set its field properly before returning it. We return VertexT * instead of VertexT to avoid the copying of a potentially large vertex object, and vertex deletion is automatically handled by our system.
The second function defines what to write to HDFS (using BufferedWriter& writer) for a processed vertex VertexT* v. This function is called for each vertex after the graph computation is done.
Combiner
We assume users are familiar with the concept of message combiner. Otherwise, you may check Section 3.2 of this paper. The Combiner class has only one abstract function for users to specify:
void combine(MessageT& old_msg, MessageT& new_msg)
Here, MessageT& old_msg refers to the combined message. When a vertex in the current worker sends a message to vertex tgt, the system checks whether it is the first message on this worker targeted at tgt. If so, it becomes old_msg; otherwise, combine(old_msg, new_msg) is called to combine that message (i.e. new_msg) with the combined message (i.e. old_msg).
Aggregator
We assume users are familiar with the concept of aggregator. Otherwise, you may check Section 3.3 of this paper. The Aggregator class has five abstract functions for users to specify:
void init()
void stepPartial(VertexT* v)
void stepFinal(PartialT* p)
PartialT* finishPartial()
FinalT* finishFinal()
We illustrate the usage of the above functions by describing how our aggregator works. One may then check some of our application codes that use aggregator to better understand its usage.
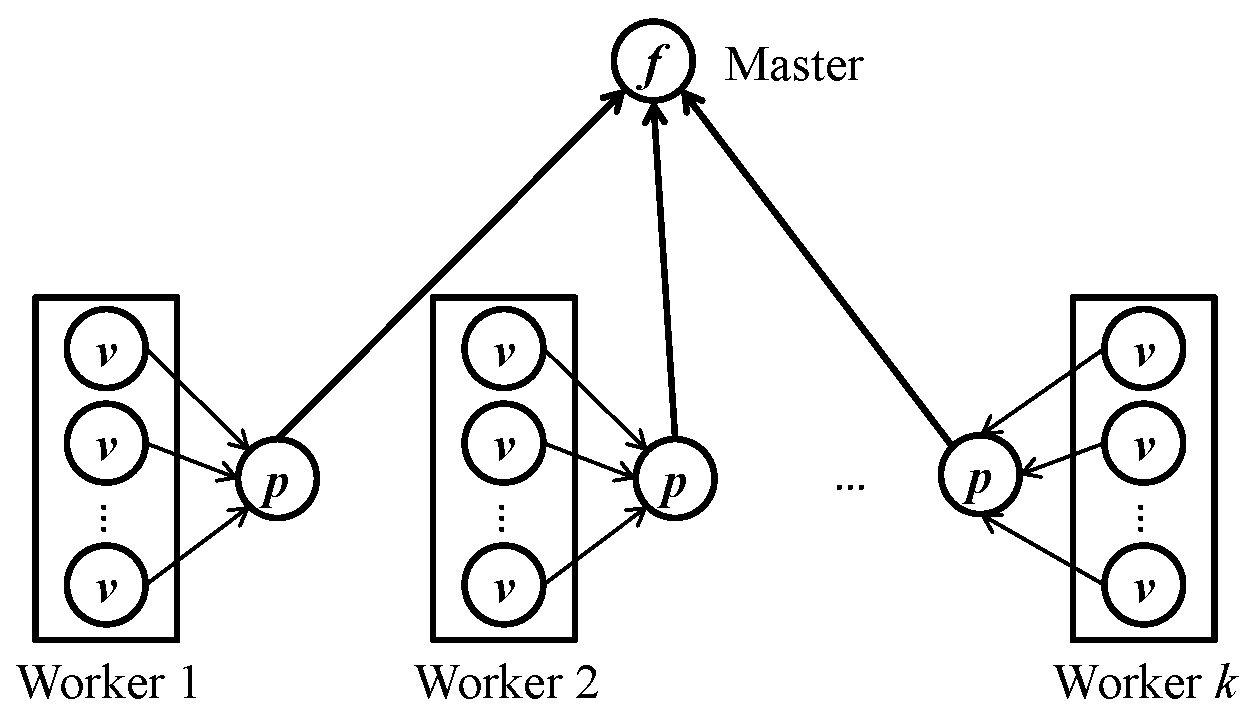
Each worker maintains an aggregator object. At the beginning of a superstep (before vertex-centric computation), the aggregator object calls init() to initialize its state. Then, for each vertex v that is active at the beginning of the superstep, v.compute() is first called, followed by the aggregator calling stepPartial(v). In stepPartial(v), the aggregator checks v's state (which may already be updated by v.compute()) and updates its own state. Note that stepPartial(v) is called as long as v is active at the begnning of the superstep, even when v votes to halt in compute(). After vertex computation finishes, the system calls finishPartial() to obtain the partially aggregated state (of type PartialT) for each worker. This partially aggregated state is presented as the circles marked with p in the above figure.
Before the next superstep begins, the partially aggregated value p of each worker is sent to the master, where the master calls stepFinal(PartialT* p) to update the state of its aggregator with that of p (note that our system makes master also a worker, which processes a fraction of vertices and has its own aggregator object). After stepFinal(PartialT* p) is called for all partially aggregated values, the master calls finishFinal() to obtain the final aggregated value (i.e. the circle marked with f in the above figure) and broadcasts it back to each worker. If one wants to post-process the aggregated result before the next superstep, one may do that in finishFinal() (which is similar to the master-compute functionality of Giraph and GPS).
If you have many vertex states to aggregate (possibly with different logic), you may implement them as the fields of your Aggregator subclass and implement the abstract functions to update them properly.
Part II: Graph Partitioning
In vertex-centric computation, each line from the input graph data on HDFS represents one vertex. However, this format cannot be directly used for block-centric computation. Blogel provides two kinds of "partitioners" to partition the vertices of the input graph into blocks. The output of a partitioner can be directly used for block-centric computation. However, we require that the number of workers used for graph partitioning be the same as that used for block-centric computation; see for the reason.
Graph Voronoi Diagram (GVD) Partitioner
This partitioner is defined in "blogel/Voronoi.h". Please first read Section 7.1 of the Blogel paper to get familiar with its partitioning algorithm before reading the following user-interface explanation.
BPartVertex
Recall that our GVD partitioner first uses multi-source BFS to compute the graph Voronoi diagram for multiple rounds, and then run a round of Hash-Min at last. These are all vertex-centric computation, where each vertex is an object of the system-defined BPartVertex class, which is a subclass of Vertex with integer ID and with value field <V> defined by the BPartValue class. To use the GVD partitioner, users only need to be familiar with the structure of the BPartValue class, which has four fields as described below:
VertexID color; //block ID, written by GVD partitioner after graph partitioning
vector<VertexID> neighbors; //a list of neighbors' IDs, set by users before graph partitioning
vector<triplet> nbsInfo; //a list of neighbors' <vertexID, blockID, workerID> triplets, written by GVD partitioner after graph partitioning
string content; //a string buffer for storing other information irrelevant to GVD partitioning (but may be useful in block-centric computing later)
Note that the type VertexID is defined to be the 32-bit int type in "utils/global.h", while one may redefine it to be long long to use 64 bits. The type triplet is defined in "blogel/BType.h", which has three integer fields <vid, bid, wid>, and we use this type for vertex ID <I> in block-centric computing later. Note that we store the worker ID inside a vertex's triplet ID, so that during block-centric computing, the system knows which machine a message to the vertex should be sent to (i.e., hash(<I>) = <I>.workerID).
BPartWorker
While a user need to be familiar with the structure of BPartVertex and BPartValue, he/she actually subclasses the BPartWorker class to use the GVD partitioner. The BPartWorker class has two abstract functions for users to specify:
BPartVertex* toVertex(char* line)
void toline(BPartVertex* v, BufferedWriter& writer)
The first function defines how to parse a line from the input graph data on HDFS into a vertex object of type BPartVertex used for GVD partitioning. Here, users need to set the fields BPartVertex::id (i.e. vertex ID) and BPartVertex::value().neighors (i.e. neighbors' IDs) properly, where BPartVertex::value() is of type BPartValue. Moreover, additional information such as edge length can be added to BPartVertex::value().content for later use.
For GVD partitioning is done, BPartVertex::value().color and BPartVertex::value().nbsInfo should already be set for every vertex, and the second function specifies how to write these information of each vertex as a line to HDFS. One may also add back those information in BPartVertex::value().content such as edge length.
After both functions are properly specified, one may set the GVD partitioning parameters properly, and then call BPartWorker::run() to start the GVD partitioning. The functions for parameter setting are given as follows (Section 7.1 of the Blogel paper for the concrete meaning of each parameter):
set_sampRate(psamp) //e.g., psamp = 0.001
set_maxHop(δmax) //e.g., δmax = 10
set_maxVCSize(bmax) //e.g., bmax = 100000
set_factor(f) //e.g., f = 2.0
set_stopRatio(γ) //e.g., γ = 0.9
set_maxRate(pmax) //e.g., pmax = 0.1
2D Partitioner
This partitioner requires two rounds, defined by "blogel/STRPart.h" and "blogel/STRPartR2.h", respectively. The first round partitions the vertices into rectangular cells, while the second round further splits the vertices in each cell into connected blocks. Please first read Section 7.2 of the Blogel paper to get familiar with its partitioning algorithm before reading the following user-interface explanation.
STRVertex & STRWorker
The STRVertex class has seven fields as described below:
VertexID id; //Vertex ID, set by users before partitioning
int bid; //cell/super-block ID, written by round 1 of 2D partitioner after partitioning
vector<VertexID> neighbors; //a list of neighbors' IDs, set by users before partitioning
vector<triplet> nbsInfo; //a list of neighbors' <vertexID, cellID, workerID> triplet IDs, written by round 1 of 2D partitioner after partitioning
double x; //vertex's x-coordinate, set by users before partitioning
double y; //vertex's y-coordinate, set by users before partitioning
string content; //a string buffer for storing other information irrelevant to 2D partitioning (but may be useful in block-centric computing later)
Compared with the BPartVertex class previously mentioned, users need to additional set the (x, y)-coordinates of each vertex, which is a prerequisite for using 2D partitioning. The first round of 2D partitioning is carried out by subclassing the STRWorker class and implementing the following two abstract functions:
STRVertex* toVertex(char* line)
void toline(STRVertex* v, BufferedWriter& writer)
The second function writes the computed fields like STRVertex::bid and STRVertex::nbsInfo into the output line for each vertex, which is prepared as the input line to round 2 of 2D partitioner.
One may then create an object of the STRWorker subclass, with partitioning parameters properly, and call STRWorker::run() to start the partitioning. The parameters are provided as the input arguments of STRWorker's constructor shown below (see Section 7.2 of the Blogel paper for the concrete meaning of the parameters):
STRWorker(int xnum, int ynum, double sampleRate) //e.g., nx = ny = 20, psamp = 0.01
STR2Vertex & STR2Worker
The STR2Vertex class is a subclass of the BVertex<I, V, M> class to be described shortly, with <I> = VertexID and <V> defined by the STR2Value class that contains the following three fields of interest:
int new_bid; //block ID, to be computed by round 2 of 2D partitioning
vector<triplet> neighbors; //(1) before partitioning, it is a list of neighbors' <vertexID, cellID, workerID> triplet IDs set by users according to the results of round 1; (2) after partitioning, it is a list of neighbors' <vertexID, blockID, workerID> triplet IDs computed by round 2.
string content; //a string buffer for storing other information irrelevant to 2D partitioning (but may be useful in block-centric computing later)
The second round of 2D partitioning is carried out by subclassing the STR2Worker class and implementing the following two abstract functions:
STR2Vertex* toVertex(char* line)
void toline(STR2Block* b, STR2Vertex* v, BufferedWriter& writer)
The first function specifies how to parse a line output by round 1 into a vertex object of type STR2Vertex, where users should set BVertex::id (vertex ID), BVertex::bid (cell ID), BVertex::wid (worker ID) of the current vertex (note that STR2Vertex is a subclass of BVertex), and the neighbor information STR2Vertex::value().neighbors and possibly STR2Vertex::value().content. One may then call STR2Worker::run() to start the partitioning.
Part III: Block-Centric Computation
The block-centric computation may proceed in one of three modes: B-mode, V-mode and VB-mode. Please first read Sections 4 and 5.2 of the Blogel paper to get familiar with the concepts of block-centric computing before reading the following user-interface explanation.
BVertex
This class is defined in "blogel/BVertex.h", and acts as a counterpart of the Vertex class in vertex-centric computing. The differences are summarized as follows. Firstly, besides the vertex ID of type <I>, an BVertex object as maintains two additional integer fields:
int bid; //block ID of the current vertex
int wid; //worker ID of (the block of) the current vertex
Secondly, to send a message msg to a target vertex tgt located on worker w(tgt), the vertex needs to call the following function that includes the target worker information:
send_message(tgt, w(tgt), msg)
Note that w(tgt) is stored in the triplet ID of tgt and thus can be easily accessed (e.g., from the adjacency list of the current vertex).
Block
This class is defined in "blogel/Block.h", which describes a block of vertices. The class has three template arguments:
BValT //the type of the block's value field
BVertexT //the type of the vertices that the block contains (subclass of BVertex)
BMsgT //the type of block-wise messages
The following three fields of the Block class are of interest:
int bid; //block ID
int begin;
int size;
//each worker contains a "vertexes" array, and the current block contains vertices vertexes[begin], vertexes[begin + 1], ..., vertexes[begin + size - 1]
Moreover, like BVertex, Block also has an abstract compute() function, and can send messages and vote to halt. We show some important interfaces below:
compute(vector
send_message(int bid, const int wid, const BMsgT& msg) //"bid" is the target vertex's block ID, while "wid" is its worker ID
BWorker
The BWorker class is defined in "blogel/BWorker.h", and it takes the user-defined Block subclass as an argument, and has two abstract functions for users to specify:
VertexT* toVertex(char* line)
void toline(BlockT* b, VertexT* v, BufferedWriter& writer) //for dumping v's information, "b" is the block of "v"
void blockInit(vector
Here, the third function is used to initialize each block object using its vertices, where "vertexList" and "blockList" are the vertex and block array of the current worker, respectively. After the vertices are loaded, each worker will automatically construct its block array from the vertex array, and set the "bid", "start", "size" fields of each blocks properly. However, for user-defined block field of type <BValT>, users need to initialize the field themselves using the blockInit() function, which is called before graph computing.
Before calling BWorker::run() to start the computation, users need to specify the running mode (using the following function), the default setting of which is B-mode.
void set_compute_mode(int mode) //mode = BWorker::B_COMP, or BWorker::V_COMP, or BWorker::VB_COMP
In block-centric computing, there are two kinds of messages: vertex-wise messages and block-wise messages. One may call the following two functions to specify combiners for the two kinds of messages.
void setCombiner(Combiner
void setBCombiner(Combiner
BAggregator
If aggregator is used, BWorker provides a second argument <AggregatorT> to specify the aggregator type. One may set the aggregator by the following function:
void setAggregator(AggregatorT* ag)
Here, the aggregator should be a subclass of BAggregator defined in "BAggregator.h", which has the following six abstract function:
void init()
void stepPartialV(VertexT* v)
void stepPartialB(BlockT* b)
void stepFinal(PartialT* p)
PartialT* finishPartial()
FinalT* finishFinal()
Compared with the vertex-centric Aggregator class, the difference of BAggregator is that the "stepParital" function now has two versions, one called on each active vertex, and the other called on each active block.
(De)Serialization
In a distributed system, in order to send a main-memory object to another machine, one needs to define how to map the object into its serial representation (and vice versa). The main-memory object is first serialized to a binary stream, which is sent to the target machine; after receiving the binary stream, the receiving machine deserializes the stream to obtain the main-memory object.
In Java-based systems such as Hadoop and Giraph, this is achieved by the Writable interface. Any type of object that needs to be sent through the network should implement the Writable interface. For example, if an integer needs to be transmitted though the network, one should use IntWritable instead of simply using int.
In Pregel+, we are able to decouple the (de)serialization operation from the object type, thanks to C++'s support of operator overloading. Specifically, one may use any data type in their code, and if the data needs to be transmitted over the network, one needs to define the (de)serialization function for its type by overloading the operators << and >>. For example, if we have a type (C/C++ basic data type, struct, or class) T that should be serializable, we define the following two functions:
obinstream& operator>>(obinstream& m, T& data)
ibinstream& operator<<(ibinstream& m, const T& data)
Here, the usage is similar to cout<< and cin>>, except that we are writing binary streams instead of text streams. We were careless during the design and the name obinstream and ibinstream are reversed from their meaning, but we leave them as they are, since revising them involves updating a lot of places throughout the system and application codes. The first function specifies how to serialize data to the input stream m, which is then sent to the target machine. The second function specifies how to deserialize the received output stream m to obtain the object data. After users define the (de)serialization operations, the system knows how to convert T-typed object to/from the serial data streams.
For basic C/C++ data types such as int, double and std::string, users can directly call m<<data and m>>data since they are already defined in utils/serialization.h. Similarly, utils/serialization.h also defines (de)serialization functions for STL containers such as std::vector<T> and __gnu_cxx::hash_map<K, V>. As long as the template argument(s) are serializable, the container type is serializable. For example, one can directly call m<<data for data of type std::vector<int> since int is serializable.
In most cases, the (de)serialization functions are called by the system rather than users. However, one may need to define the (de)serialization functions for user-defined types, where the predefined (de)serialization functions can be used in a recursive manner. For example, suppose that we have a type:
struct my_type
{
int state;
vector<int> out_neighbors;
};
We may define the (de)serialization functions of my_type using the predefined (de)serialization functions of its components as follows:
obinstream& operator>>(obinstream& m, my_type& data)
{
m >> state;
m >> out_neighbors;
return m;
}
ibinstream& operator<<(ibinstream& m, const my_type& data)
{
m << state;
m << out_neighbors;
return m;
}
We now use class Vertex<I, V, M> in basic/Vertex.h to illustrate what types should be serializable. If the (de)serialization functions are not defined for those types, the application code cannot pass compilation. Firstly, each vertex should be serializable, since after vertices are loaded in parallel by different workers from HDFS, they need to be exchanged though the network, so that finally each worker w only holds those vertices v with hash(v) = w before graph computation. In our system, the user-defined Vertex subclass is serializable, as long as all its template arguments <I>, <V>, <M> are serializable, which should be guaranteed by users. In contrast, the BVertex class need not be serializable, since each worker directly loads the graph partition on HDFS which is assigned to the worker by partitioners, and no vertex exchange is necessary. Secondly, since the computation is done by message passing, the message types <M> and <BMsgT> should be serializable. Thirdly, if aggregator is used, a partially aggregated value of type PartialT should be serializable since it is sent from a worker to the master though the network; similarly, the final aggregated value of type FinalT should be serializable, since it is broadcast back from the master to all workers though the network.
Communication
All the communication operations are handled by the system itself, and application programmers may safely skip this part. For those who would like to change or extend the system code, we provide more details here.